自己做网站做什么内容搜狐视频
【摘要】本文来自Mybridge,介绍了过去一年里30个惊艳的Python开源项目。点击阅读原文每一个都可以在GitHub上看到更为详细的内容。以下是译文。

在过去的一年里,Mybridge AI 比较了近15000个开源Python项目,选择了前30名(概率只有0.2%)。
这是一个竞争异常激烈的名单,精挑细选了2017年1月到12月之间发布的最佳开源Python库、工具和应用程序。Mybridge AI 通过考量受欢迎程度、参与度和新近度等指标来评估这些参选项目的质量。这些项目在Github上得星的数量平均为3,707个。
开源项目对于程序员来说可能大有裨益。通过阅读源代码并在现有项目之上构建一些东西。是该拿出时间来玩玩过去一年中可能错过的Python项目啦!
Python开源项目排行榜
第一名
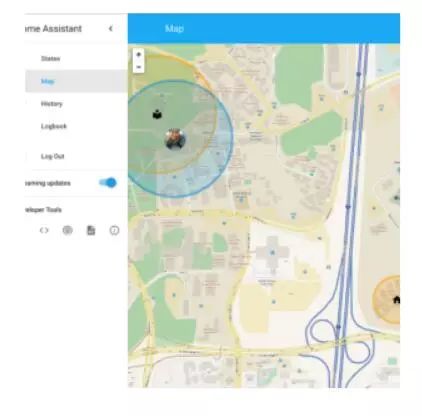
家庭助理(v0.6+):开源家庭自动化平台
在Python 3上运行[Github上11357颗星]。由Paulus Schoutsen提供
第二名
Pytorch:强GPU加速Python中的Tensor和动态神经网络[Github上11019颗星]。由Adam Paszke 和pytorch团队其他成员提供

第三名
Grumpy:一个Python源代码反编译和运行[Github上8367颗星]。由Dylan Trotter和Google的其他成员提供

第四名
Sanic:异步Python3.5+Web服务器加速[Github上8028颗星]。由Channel Cat和Eli Uriegas提供

第五名
Python—fire:从任意Python对象中自动生成命令行接口(CLIs)的库[Github上7775颗星]。由David Bieber和来自Google Brain(Google Brain是Google内部用于训练大规模深度神经网络的构架,它为用户提供了方便的API)的其他成员提供

第六名
spaCy(v2.0):用Python和Cython实现工业强度的自然语言处理(NLP)[Github上7663颗星]。由Matthew Honnibal提供

第七名
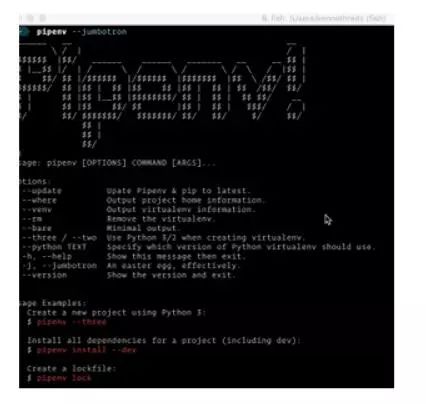
Pipenv:人类的Python开发工作流[Github上7273颗星]。由Kenneth Reitz提供
第八名
MicroPython:简单和高效的Python实现微控制和约束系统[Github上5728颗星]

第九名
Prophet:生成具有线性或非线性增长的多重季节性的时间序列数据的高质量预测工具[Github上4369颗星]。由Facebook提供

第十名
SerpentAI:用Python编写的游戏代理框架。帮助创建Ais/Bots,可以玩任意游戏[Github上3411颗星]。由Nicholas Brochu提供

第十一名
Dash:用纯Python编写的交互的、实时响应的Web应用程序[Github上3281颗星]。由Chris P提供

第十二名
InstaPy:Instagram Bot. Like/Comment/Follow自动化脚本。[Github上3179颗星]。由TImG提供

第十三名
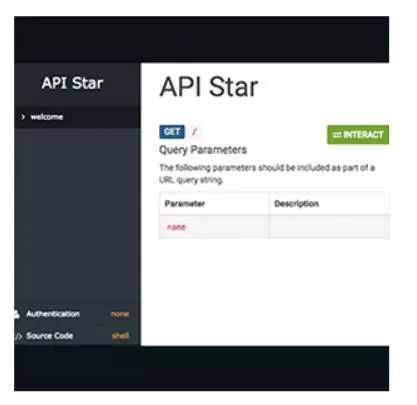
Apistar:一个快速的和有表现力的API框架。用于Python**[Github上3024颗星]**。由Tom Christie提供
第十四名
Faiss:有效相似性搜索和密集向量集群的库[Github上2717颗星]。由Matthijs Douze和来自Facebook研究院的其他成员提供

第十五名
MechanicalSoup:一个与网站自动化交互的Python库[Github上2244颗星]。

第十六名
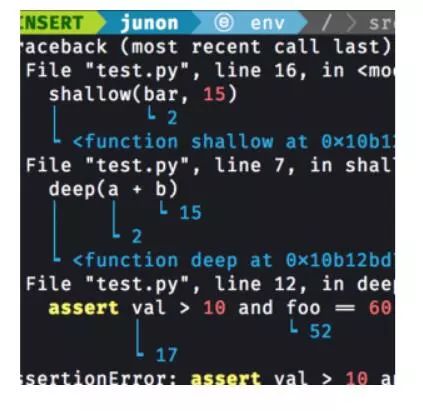
Better-exceptions:用Python编写的自动地漂亮的和有用的异常处理[Github上2121颗星]。由Qix提供
第十七名
Flashtext:从句子中提取关键词或替换句子中的关键词[Github上2019颗星]。由Vikash Singh提供
第十八名
Maya:用Python实现人类的日期时间[Github上1828颗星]。由Kenneth Reitz提供

第十九名
Mimesis (v1.0):Python库,有助于为不同的目的以不同的语言生成模拟数据。这些数据在软件开发和测试的不同阶段特别有用[Github上1732颗星]。由Líkið Geimfari 提供

第二十名
开放式无纸化:扫描、索引和归档所有的纸质文档。一个文档管理系统[Github上1717颗星]。由Tina Zhou提供

第二十一名
Fsociety:黑客工具包。渗透测试框架[Github上1585颗星]。由Manis Manisso提供
第二十二名
LivePython:实时可视化跟踪Python代码[Github上1577颗星]。由Anastasis Germanidis提供
第二十三名
Hatch:用于Python的现代项目、包和虚拟环境管理器[Github上1537颗星]。由Ofek Lev提供

第二十四名
Tangent:用纯Python实现源到源的可调试导数[Github上1433颗星]。由Alex Wiltschko和来自Google Brain其他成员提供
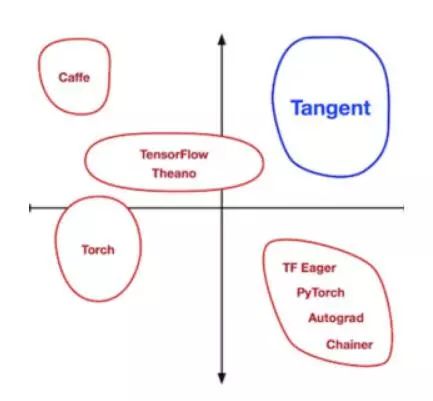
第二十五名
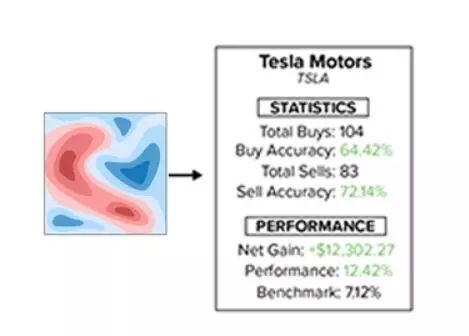
Clairvoyant:识别和监控短期股票走势的历史线索的Python程序[Github上1159颗星]。由Anthony Federico提供
第二十六名
MonkeyType:Python通过收集运行时类型生成静态类型注释的系统[Github上1143颗星]。由Instagram工程组的Carl Meyer提供
第二十七名
Eel:一个小的Python库,用于制作简单的电子类HTML / js GUI应用程序[Github上1137颗星]。

第二十八名
Surprise v1.0:建立和分析推荐系统的Python scikit**[Github上1103颗星]**。

第二十九名
Gain:获取每个人的Web爬行框架[Github上1009颗星]。由高久力提供

第三十名
PDFTabExtract: 一组从PDF文件中提取表的工具,有助于对扫描文档进行数据挖掘[Github上722颗星]。

这就是Python2017年度开源项目。可以在Mybridge网站上基于自己的编程技能读最好的日常文章。