免费在线观看电视剧的网站辽宁建设工程信息网评标专家账号找回
在 Azure AI 搜索中,语义排名是查询端功能,它使用 Microsoft AI 对搜索结果重新评分,将具有更多语义相关性的结果移动到列表顶部。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
环境准备
-
具有活动订阅的 Azure 帐户。 免费创建帐户。
-
Azure AI 搜索,位于基本层或更高层级,且[已启用语义排名]。
-
API 密钥和搜索服务终结点:
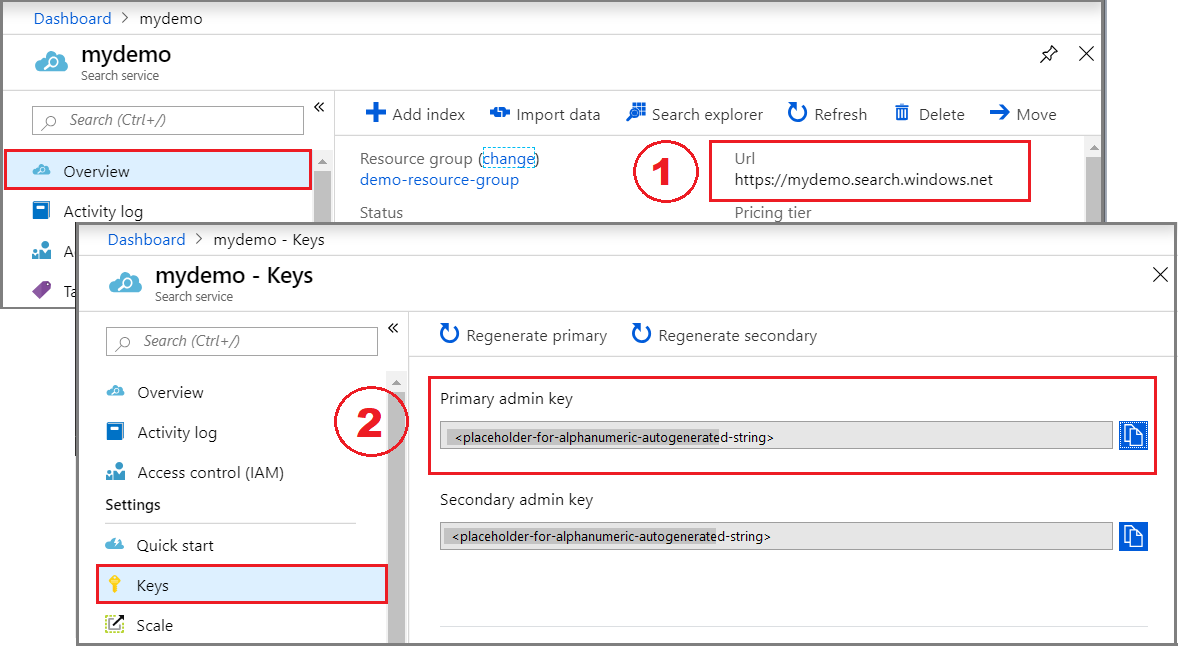
登录到 Azure 门户并查找你的搜索服务。
在“概述”中,复制 URL 并将其保存到记事本以供后续步骤使用。 示例终结点可能类似于
https://mydemo.search.windows.net。在“密钥”中,复制并保存管理密钥,以获取创建和删除对象的完整权限。 有两个可互换的主要密钥和辅助密钥。 选择其中一个。
添加语义排名
要使用语义排名,请将_语义配置_添加到搜索索引,并将参数添加到查询。 如果有现有索引,可以进行这些更改,无需重新编制内容索引,因为不会影响可搜索内容的结构。
-
语义配置为提供在语义重新排名中使用的标题、关键字和内容的字段建立优先级顺序。 字段优先级允许更快的处理。
-
调用语义排名的查询包括查询类型、查询语言以及是否返回字幕和答案的参数。 可以将这些参数添加到现有的查询逻辑。 与其他参数没有冲突。
设置你的环境
我们使用以下工具创建了本快速入门。
-
带有 Python 扩展的 Visual Studio Code(或等效的 IDE),Python 版本为 3.7 或更高
-
用于 Python 的 Azure SDK 中的 azure-search-documents 包
连接到 Azure AI 搜索
在此任务中,创建笔记本、加载库并设置客户端。
-
在 Visual Studio Code 中创建新的 Python3 笔记本:
- 按 F1 并搜索“Python 选择解释器”,然后选择 Python 3.7 版本或更高版本。
- 再次按 F1 并搜索“创建:新的 Jupyter Notebook”。 应在编辑器中打开一个空的无标题
.ipynb文件,为第一个条目做好准备。
-
在第一个单元格中,从用于 Python 的 Azure SDK 加载库,包括 [azure-search-documents]。 此代码导入 “SemanticConfiguration”、“PrioritizedFields”、“SemanticField” 和 “SemanticSettings”。
%pip install azure-search-documents --pre %pip show azure-search-documents %pip install python-dotenvimport os from azure.core.credentials import AzureKeyCredential from azure.search.documents.indexes import SearchIndexClient from azure.search.documents import SearchClient from azure.search.documents.indexes.models import ( SearchIndex, SearchField, SearchFieldDataType, SimpleField, SearchableField,ComplexField,SearchIndex, SemanticConfiguration, PrioritizedFields, SemanticField, SemanticSettings, ) -
从环境中设置服务终结点和 API 密钥。 由于代码为你生成了 URI,因此只需在服务名称属性中指定搜索服务名称。
service_name = "<YOUR-SEARCH-SERVICE-NAME>" admin_key = "<YOUR-SEARCH-SERVICE-ADMIN-KEY>"index_name = "hotels-quickstart"endpoint = "https://{}.search.windows.net/".format(service_name) admin_client = SearchIndexClient(endpoint=endpoint,index_name=index_name,credential=AzureKeyCredential(admin_key))search_client = SearchClient(endpoint=endpoint,index_name=index_name,credential=AzureKeyCredential(admin_key)) -
删除索引(如果存在)。 此步骤允许代码创建索引的新版本。
try:result = admin_client.delete_index(index_name)print ('Index', index_name, 'Deleted') except Exception as ex:print (ex)
创建或更新索引
-
创建或更新索引架构以包含
SemanticConfiguration和SemanticSettings。 如果要更新现有索引,此修改无需重新编制索引,因为文档的结构保持不变。name = index_name fields = [SimpleField(name="HotelId", type=SearchFieldDataType.String, key=True),SearchableField(name="HotelName", type=SearchFieldDataType.String, sortable=True),SearchableField(name="Description", type=SearchFieldDataType.String, analyzer_name="en.lucene"),SearchableField(name="Description_fr", type=SearchFieldDataType.String, analyzer_name="fr.lucene"),SearchableField(name="Category", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),SearchableField(name="Tags", collection=True, type=SearchFieldDataType.String, facetable=True, filterable=True),SimpleField(name="ParkingIncluded", type=SearchFieldDataType.Boolean, facetable=True, filterable=True, sortable=True),SimpleField(name="LastRenovationDate", type=SearchFieldDataType.DateTimeOffset, facetable=True, filterable=True, sortable=True),SimpleField(name="Rating", type=SearchFieldDataType.Double, facetable=True, filterable=True, sortable=True),ComplexField(name="Address", fields=[SearchableField(name="StreetAddress", type=SearchFieldDataType.String),SearchableField(name="City", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),SearchableField(name="StateProvince", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),SearchableField(name="PostalCode", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),SearchableField(name="Country", type=SearchFieldDataType.String, facetable=True, filterable=True, sortable=True),])] semantic_config = SemanticConfiguration(name="my-semantic-config",prioritized_fields=PrioritizedFields(title_field=SemanticField(field_name="HotelName"),prioritized_keywords_fields=[SemanticField(field_name="Category")],prioritized_content_fields=[SemanticField(field_name="Description")]) )semantic_settings = SemanticSettings(configurations=[semantic_config]) scoring_profiles = [] suggester = [{'name': 'sg', 'source_fields': ['Tags', 'Address/City', 'Address/Country']}] -
发送请求。 请注意,
SearchIndex()采用semantic_settings参数。index = SearchIndex(name=name,fields=fields,semantic_settings=semantic_settings,scoring_profiles=scoring_profiles,suggesters = suggester)try:result = admin_client.create_index(index)print ('Index', result.name, 'created') except Exception as ex:print (ex) -
如果要新建索引,请上传一些要编制索引的文档。 本文档的有效负载与全文搜索快速入门中使用的有效负载相同。
documents = [{"@search.action": "upload","HotelId": "1","HotelName": "Secret Point Motel","Description": "The hotel is ideally located on the main commercial artery of the city in the heart of New York. A few minutes away is Time's Square and the historic centre of the city, as well as other places of interest that make New York one of America's most attractive and cosmopolitan cities.","Description_fr": "L'hôtel est idéalement situé sur la principale artère commerciale de la ville en plein cœur de New York. A quelques minutes se trouve la place du temps et le centre historique de la ville, ainsi que d'autres lieux d'intérêt qui font de New York l'une des villes les plus attractives et cosmopolites de l'Amérique.","Category": "Boutique","Tags": [ "pool", "air conditioning", "concierge" ],"ParkingIncluded": "false","LastRenovationDate": "1970-01-18T00:00:00Z","Rating": 3.60,"Address": {"StreetAddress": "677 5th Ave","City": "New York","StateProvince": "NY","PostalCode": "10022","Country": "USA"}},{"@search.action": "upload","HotelId": "2","HotelName": "Twin Dome Motel","Description": "The hotel is situated in a nineteenth century plaza, which has been expanded and renovated to the highest architectural standards to create a modern, functional and first-class hotel in which art and unique historical elements coexist with the most modern comforts.","Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.","Category": "Boutique","Tags": [ "pool", "free wifi", "concierge" ],"ParkingIncluded": "false","LastRenovationDate": "1979-02-18T00:00:00Z","Rating": 3.60,"Address": {"StreetAddress": "140 University Town Center Dr","City": "Sarasota","StateProvince": "FL","PostalCode": "34243","Country": "USA"}},{"@search.action": "upload","HotelId": "3","HotelName": "Triple Landscape Hotel","Description": "The Hotel stands out for its gastronomic excellence under the management of William Dough, who advises on and oversees all of the Hotel's restaurant services.","Description_fr": "L'hôtel est situé dans une place du XIXe siècle, qui a été agrandie et rénovée aux plus hautes normes architecturales pour créer un hôtel moderne, fonctionnel et de première classe dans lequel l'art et les éléments historiques uniques coexistent avec le confort le plus moderne.","Category": "Resort and Spa","Tags": [ "air conditioning", "bar", "continental breakfast" ],"ParkingIncluded": "true","LastRenovationDate": "2015-09-20T00:00:00Z","Rating": 4.80,"Address": {"StreetAddress": "3393 Peachtree Rd","City": "Atlanta","StateProvince": "GA","PostalCode": "30326","Country": "USA"}},{"@search.action": "upload","HotelId": "4","HotelName": "Sublime Cliff Hotel","Description": "Sublime Cliff Hotel is located in the heart of the historic center of Sublime in an extremely vibrant and lively area within short walking distance to the sites and landmarks of the city and is surrounded by the extraordinary beauty of churches, buildings, shops and monuments. Sublime Cliff is part of a lovingly restored 1800 palace.","Description_fr": "Le sublime Cliff Hotel est situé au coeur du centre historique de sublime dans un quartier extrêmement animé et vivant, à courte distance de marche des sites et monuments de la ville et est entouré par l'extraordinaire beauté des églises, des bâtiments, des commerces et Monuments. Sublime Cliff fait partie d'un Palace 1800 restauré avec amour.","Category": "Boutique","Tags": [ "concierge", "view", "24-hour front desk service" ],"ParkingIncluded": "true","LastRenovationDate": "1960-02-06T00:00:00Z","Rating": 4.60,"Address": {"StreetAddress": "7400 San Pedro Ave","City": "San Antonio","StateProvince": "TX","PostalCode": "78216","Country": "USA"}} ] -
发送请求。
try:result = search_client.upload_documents(documents=documents)print("Upload of new document succeeded: {}".format(result[0].succeeded)) except Exception as ex:print (ex.message)
运行查询
-
从空查询开始(作为验证步骤),证明索引可操作。 应获得酒店名称和说明的无序列表,计数为 4,表示索引中有四个文档。
results = search_client.search(query_type='simple',search_text="*" ,select='HotelName,Description',include_total_count=True)print ('Total Documents Matching Query:', results.get_count()) for result in results:print(result["@search.score"])print(result["HotelName"])print(f"Description: {result['Description']}") -
出于比较目的,请执行调用全文搜索和 BM25 相关性评分的基本查询。 提供查询字符串时,会调用全文搜索。 响应包括排名结果,其中较高的分数会授予具有更多匹配字词实例或更重要字词的文档。
在此查询“哪家酒店现场有不错的餐厅”中,Sublime Cliff Hotel 脱颖而出,因为它的说明中包含“现场”。 不经常出现的字词会提高文档的搜索分数。
results = search_client.search(query_type='simple',search_text="what hotel has a good restaurant on site" ,select='HotelName,HotelId,Description')for result in results:print(result["@search.score"])print(result["HotelName"])print(f"Description: {result['Description']}") -
现在添加语义排名。 新参数包括
query_type和semantic_configuration_name。这是同一个查询,但请注意,语义排名器将 Triple Landscape Hotel 正确识别为更相关的结果(鉴于初始查询)。 此查询还会返回模型生成的标题。 此示例中的输入太少,无法创建有趣标题,但该示例成功演示了语法。
results = search_client.search(query_type='semantic', semantic_configuration_name='my-semantic-config',search_text="what hotel has a good restaurant on site", select='HotelName,Description,Category', query_caption='extractive')for result in results:print(result["@search.reranker_score"])print(result["HotelName"])print(f"Description: {result['Description']}")captions = result["@search.captions"]if captions:caption = captions[0]if caption.highlights:print(f"Caption: {caption.highlights}\n")else:print(f"Caption: {caption.text}\n") -
在此最终查询中,会返回语义答案。
语义排名可以生成具有问题特征的查询字符串的答案。 生成的答案从内容中逐字提取。 要获取语义答案,问题和答案必须密切一致,并且模型必须找到明确回答问题的内容。 如果可能的答案无法满足置信度阈值,模型不会返回答案。 出于演示目的,此示例中的问题旨在获取响应,以便你可以看到语法。
results = search_client.search(query_type='semantic', semantic_configuration_name='my-semantic-config',search_text="what hotel stands out for its gastronomic excellence", select='HotelName,Description,Category', query_caption='extractive', query_answer="extractive",)semantic_answers = results.get_answers() for answer in semantic_answers:if answer.highlights:print(f"Semantic Answer: {answer.highlights}")else:print(f"Semantic Answer: {answer.text}")print(f"Semantic Answer Score: {answer.score}\n")for result in results:print(result["@search.reranker_score"])print(result["HotelName"])print(f"Description: {result['Description']}")captions = result["@search.captions"]if captions:caption = captions[0]if caption.highlights:print(f"Caption: {caption.highlights}\n")else:print(f"Caption: {caption.text}\n")
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。