php移动网站开发免费ppt制作
一、页面设计
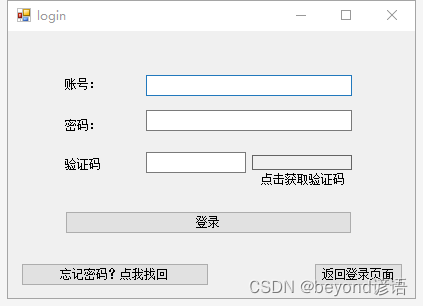
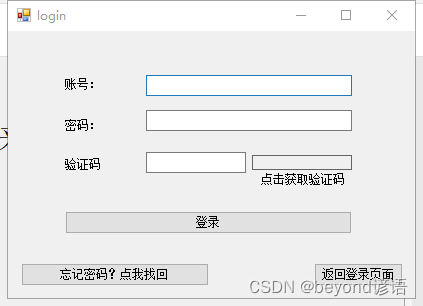
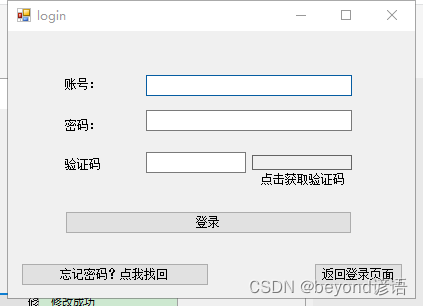
login页面,和第二篇博文(用户登录和注册)页面基本一样,只不过多了一个按钮
其中忘记密码?点我找回 为button3
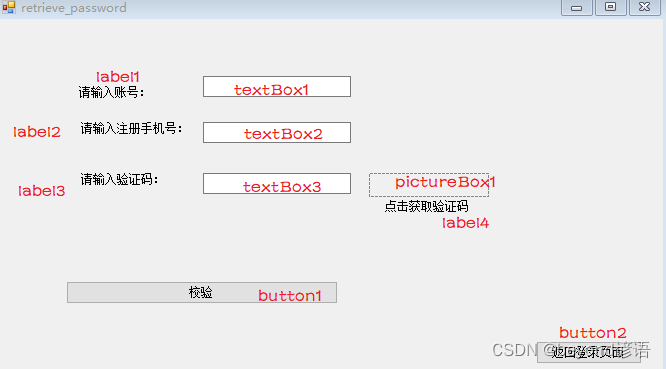
retrieve_password页面
change_password页面

页面如下:
二、数据库
因为是忘记密码,也就是修改密码而已,数据表仍为yy_user不变
id设置为主键自增
随便添加些数据
三、代码如下
login页面代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Data.OleDb;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Data.Sql;
using System.Data.SqlClient;namespace fiber_yy
{public partial class login : Form{public string name = "";public static string str_conn = "server=CY-20190824RMES;Initial Catalog=fiber_yy;User ID=sa;pwd=beyond";SqlConnection conn = new SqlConnection(str_conn);public string identification = null;public login(){InitializeComponent();}private void button1_Click(object sender, EventArgs e)//登录{conn.Open();string sex = "";string phone = "";string day = DateTime.Now.ToLocalTime().ToString();//string time = DateTime.Now.ToLongTimeString().ToString();string username = textBox1.Text;string password = textBox2.Text;string identify = textBox3.Text;if (username.Equals("") || password.Equals("") || identify.Equals("")){MessageBox.Show("提示:请输入用户名、密码、验证码!", "警告");}else{string sqlSel = "select count(*) from yy_user where username = '" + username + "' and password = '" + password + "'";SqlCommand cmd = new SqlCommand(sqlSel, conn);if (Convert.ToInt32(cmd.ExecuteScalar()) > 0 )//账号密码正确{string sql = "select username,sex,phone from yy_user where username = '" + username + "'";SqlCommand com = new SqlCommand(sql, conn);SqlDataReader read = com.ExecuteReader();while (read.Read())//获取yy_user表中的username,sex,phone{//int number = Convert.ToInt32(read["username"]);//查询列名1的数据,方法为: read(变量名)["列名"]; 该方法返回的是object类型name = read["username"].ToString();//MessageBox.Show(name);sex = read["sex"].ToString();//MessageBox.Show(sex);phone = read["phone"].ToString();//MessageBox.Show(phone);}read.Close();if (identify==identification)//判断验证码是否输入正确{string INSERT_sql = string.Format("INSERT INTO yy_user_record VALUES ('{0}','{1}','{2}','{3}')", name,sex,phone, DateTime.Now.ToLocalTime());SqlCommand INSERT_cmd = new SqlCommand(INSERT_sql, conn);int count = INSERT_cmd.ExecuteNonQuery();if (count > 0){MessageBox.Show(name);MessageBox.Show("记录用户登录!");new main_page().Show();this.Hide();}else{MessageBox.Show("记录用户失败");}}else {MessageBox.Show("验证码输入错误");}}else{MessageBox.Show("请检查账号密码");}}}private void pictureBox1_Click(object sender, EventArgs e){Random r = new Random();string str = null;for (int i = 0; i < 5; i++){int n = r.Next(0, 10);str += n;//包括字符串在内}identification = str;Bitmap b = new Bitmap(100, 15);Graphics g = Graphics.FromImage(b);for (int i = 0; i < 5; i++){String[] fonts = { "宋体", "黑体", "隶书", "仿宋", "微软雅黑" };//字体数组Color[] colors = { Color.Red, Color.Black, Color.Blue,Color.YellowGreen ,Color.Green };//颜色数组Font f = new Font(fonts[r.Next(0, 5)], 25, FontStyle.Bold);SolidBrush s = new SolidBrush(colors[r.Next(0, 5)]);//定义一个单独的画笔,使每个字符的颜色随机Point p = new Point(i * 20, 0);//每个字符间隔20g.DrawString(str[i].ToString(), Font, s, p);}for (int a = 0; a < 5; a++){Point p1 = new Point(r.Next(0, b.Width), r.Next(0, b.Height));Point p2 = new Point(r.Next(0, b.Width), r.Next(0, b.Height));//线的两点不能超过图片的长和宽Pen pen = new Pen(Brushes.Cyan);//青色线段g.DrawLine(pen, p1, p2);}pictureBox1.Image = b;}private void button2_Click(object sender, EventArgs e){new Form1().Show();this.Hide();}private void button3_Click(object sender, EventArgs e){new retrieve_password().Show();this.Hide();}}
}retrieve_password页面代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Data.OleDb;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Data.Sql;
using System.Data.SqlClient;namespace fiber_yy
{public partial class retrieve_password : Form{public string name = "";public static string str_conn = "server=CY-20190824RMES;Initial Catalog=fiber_yy;User ID=sa;pwd=beyond";SqlConnection conn = new SqlConnection(str_conn);public string identification = null;public string phone = "";public string phone_db = "";public string username = "";public string username_db = "";public string identify = "";public retrieve_password(){InitializeComponent();}private void pictureBox1_Click(object sender, EventArgs e){Random r = new Random();string str = null;for (int i = 0; i < 5; i++){int n = r.Next(0, 10);str += n;//包括字符串在内}identification = str;Bitmap b = new Bitmap(100, 15);Graphics g = Graphics.FromImage(b);for (int i = 0; i < 5; i++){String[] fonts = { "宋体", "黑体", "隶书", "仿宋", "微软雅黑" };//字体数组Color[] colors = { Color.Red, Color.Black, Color.Blue, Color.YellowGreen, Color.Green };//颜色数组Font f = new Font(fonts[r.Next(0, 5)], 25, FontStyle.Bold);SolidBrush s = new SolidBrush(colors[r.Next(0, 5)]);//定义一个单独的画笔,使每个字符的颜色随机Point p = new Point(i * 20, 0);//每个字符间隔20g.DrawString(str[i].ToString(), Font, s, p);}for (int a = 0; a < 5; a++){Point p1 = new Point(r.Next(0, b.Width), r.Next(0, b.Height));Point p2 = new Point(r.Next(0, b.Width), r.Next(0, b.Height));//线的两点不能超过图片的长和宽Pen pen = new Pen(Brushes.Cyan);//青色线段g.DrawLine(pen, p1, p2);}pictureBox1.Image = b;}private void button1_Click(object sender, EventArgs e){username = textBox1.Text;phone = textBox2.Text;identify = textBox3.Text;//MessageBox.Show(identify);//MessageBox.Show(identification);if (identify == identification)//判断验证码是否输入正确{conn.Open();string sql = "select username,phone from yy_user where username = '" + username + "'";SqlCommand com = new SqlCommand(sql, conn);SqlDataReader read = com.ExecuteReader();while (read.Read())//获取yy_user表中的username,sex,phone{//int number = Convert.ToInt32(read["username"]);//查询列名1的数据,方法为: read(变量名)["列名"]; 该方法返回的是object类型username_db = read["username"].ToString();//MessageBox.Show(name);//sex = read["sex"].ToString();//MessageBox.Show(sex);phone_db = read["phone"].ToString();//MessageBox.Show(phone);}read.Close();MessageBox.Show(phone_db);if(phone_db==phone){//conn.Close();MessageBox.Show("校验通过");new change_password(username).Show();this.Hide();}else {MessageBox.Show("注册手机号不对");}}else{MessageBox.Show("验证码输入错误");}}private void button2_Click(object sender, EventArgs e){new login().Show();this.Hide();}}}change_password页面代码
using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Data.OleDb;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using System.Data.Sql;
using System.Data.SqlClient;
namespace fiber_yy
{public partial class change_password : Form{public string name = "";public static string str_conn = "server=CY-20190824RMES;Initial Catalog=fiber_yy;User ID=sa;pwd=beyond";SqlConnection conn = new SqlConnection(str_conn);//public string identification = null;public string password = "";public string password1 = "";public string username = "";//OleDbCommand cmd = new OleDbCommand();//cmd.Connection = conn;public change_password(){InitializeComponent();}public change_password(string yy){InitializeComponent();username = yy;}private void button1_Click(object sender, EventArgs e){MessageBox.Show(username);password = textBox1.Text;password1 = textBox2.Text;if (password.Length <= 3 || password.Length >= 16){label3.Text = "密码长度应该在3~16字符之间";}else if(password != password1){label3.Text = "两次输入密码不一致";//MessageBox.Show("两次输入密码不一致");}else if(password==password1){conn.Open();string sql = "update yy_user set password = '"+ password + "' where username = '" + username + "'";SqlCommand com = new SqlCommand(sql, conn);com.ExecuteNonQuery();//返回值为操作的条数MessageBox.Show("修改成功");conn.Close();new login().Show();this.Hide();}}}
}四、效果展示
程序运行
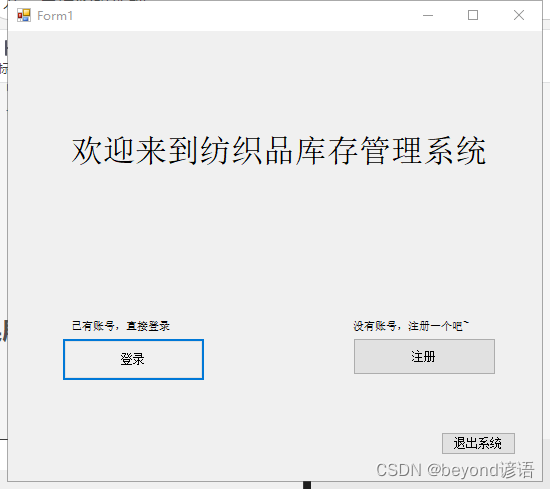
登录
忘记密码?点我找回
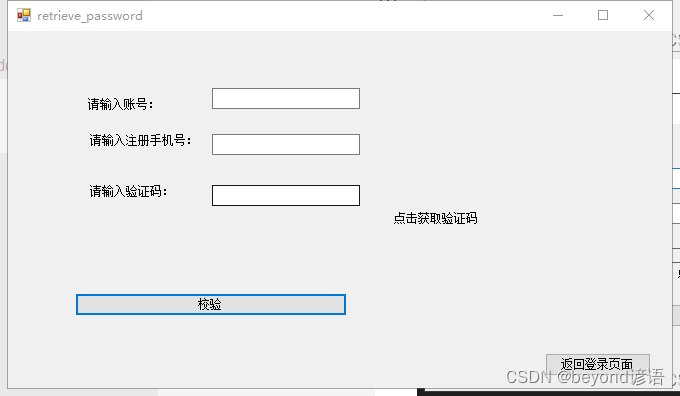
通过手机号来校验
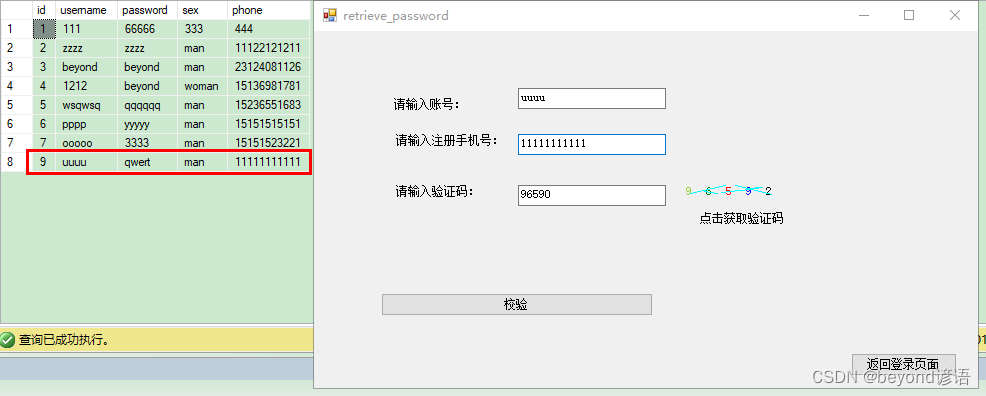
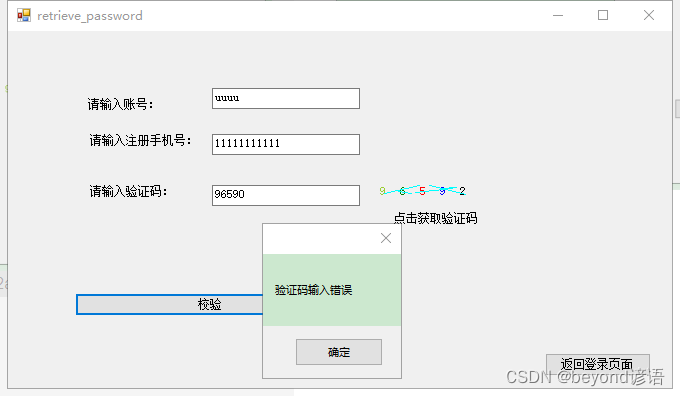
验证码输入错误
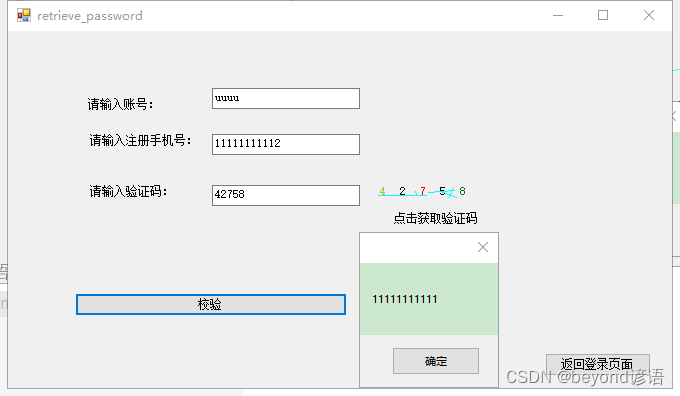
调试时输出数据库中的注册手机号
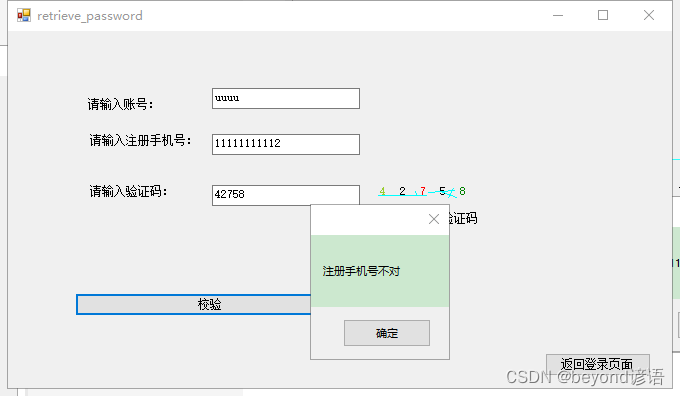
与输入框中的手机号对比
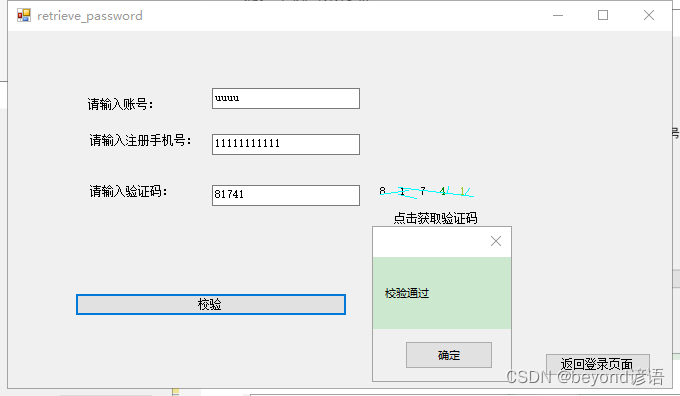
校验成功,跳转到修改密码change_password页面
两次密码必须一致
调试时,获取登录用户的账号
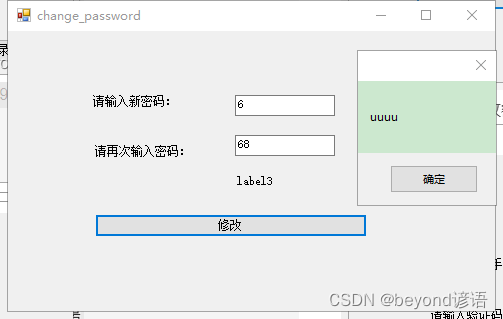
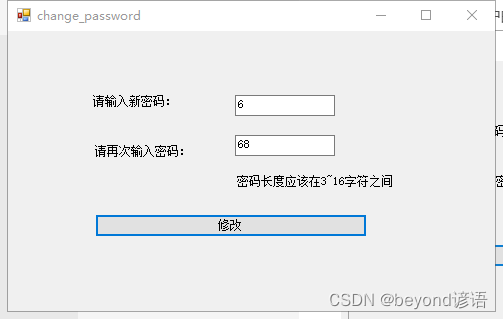
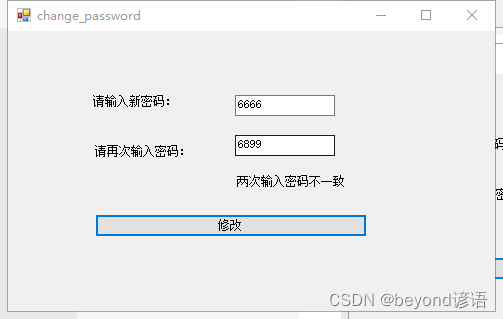
新密码必须在3-16字符之间
修改成功
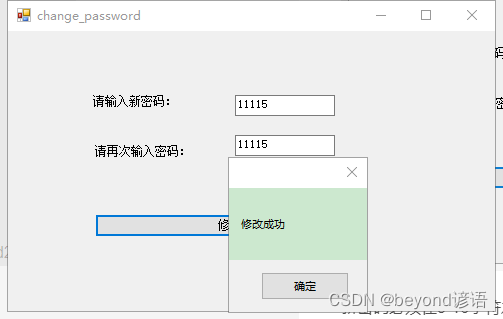
点击确定自动返回登录页面
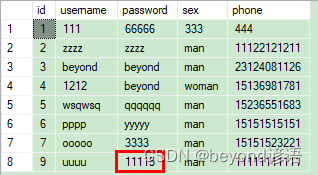
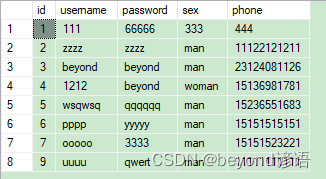
原始数据库
右击yy_user表
选择前1000行
可看到密码已经修改成功