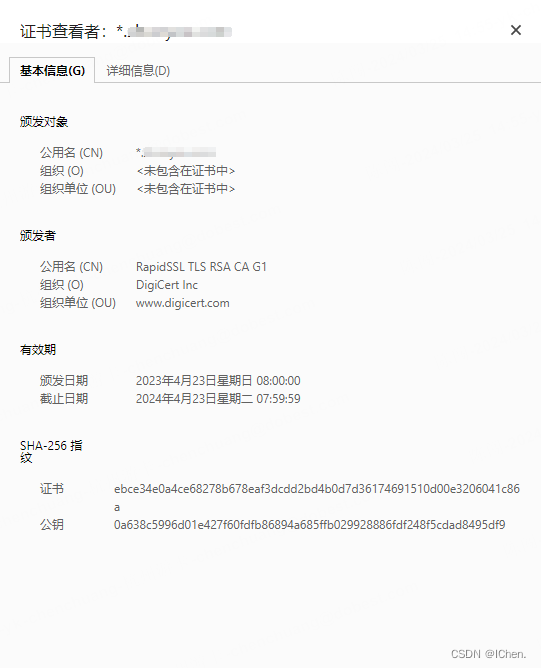
总结了下apisix 使用https 的问题和方法
1、apisix 默认https 端口是9443
2、apisix 需要上传证书后才可以使用https 否二curl测试会报错
SSL routines:CONNECT_CR_SRVR_HELLO
3、apisix 上传证书方法
我是使用的自签名证书,注意自签名证书的Common Name 要写你的域名。
自签名证书可以参考自签名证书方法
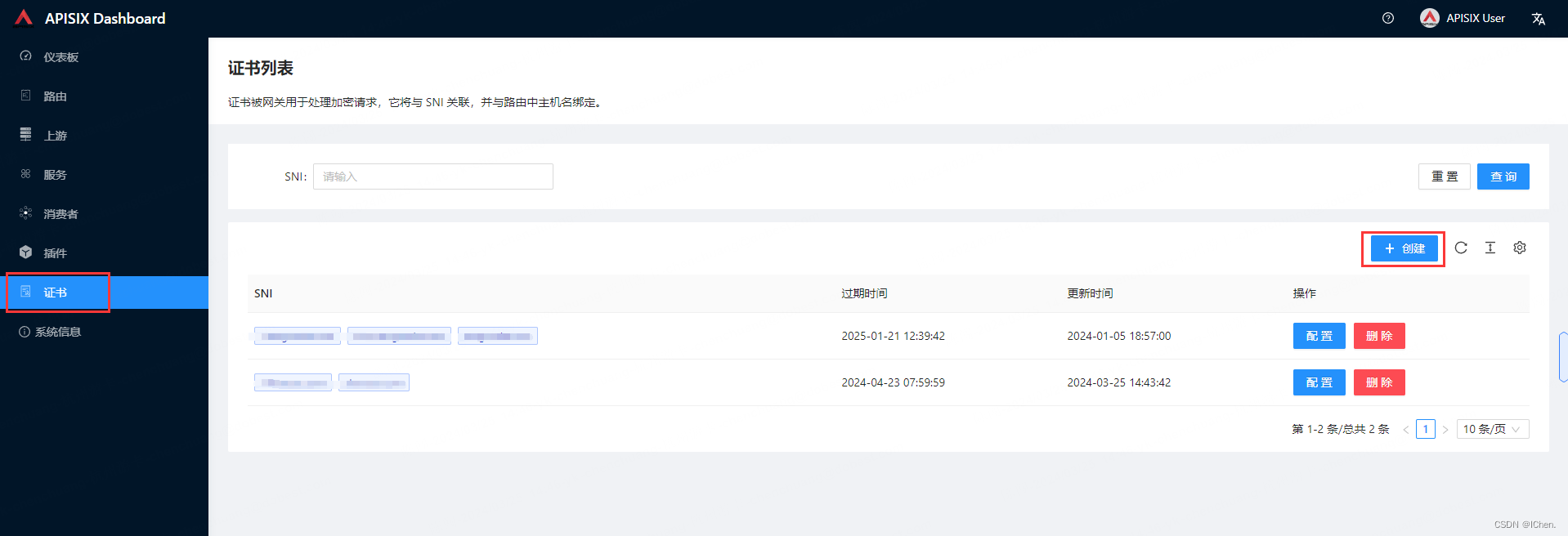
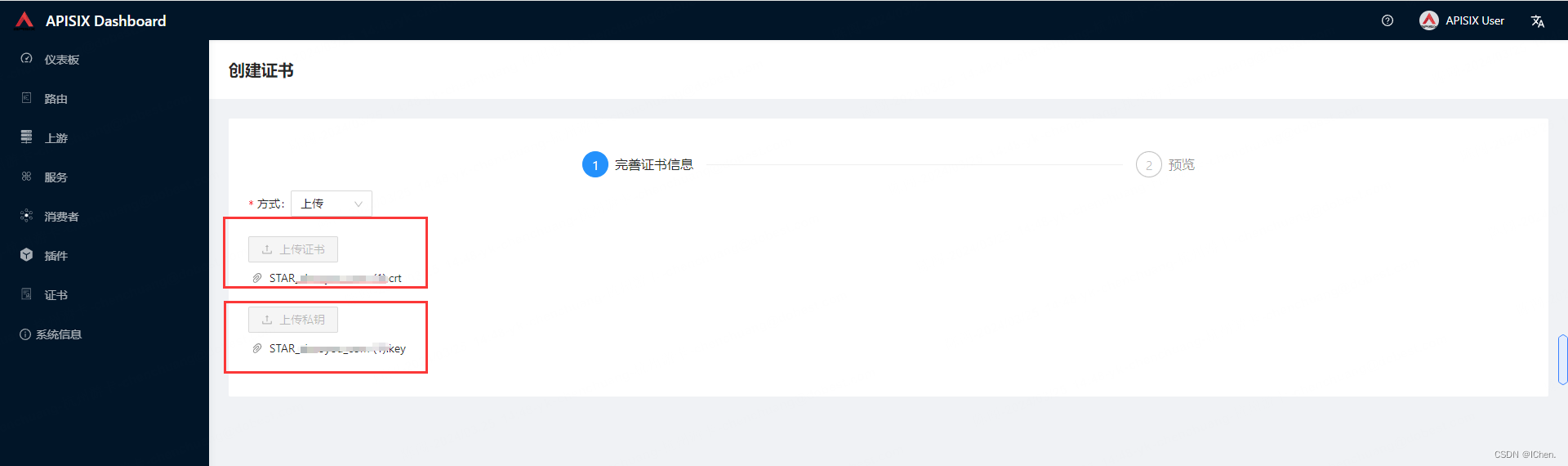
选择上传的方式,当然输入方式也可以
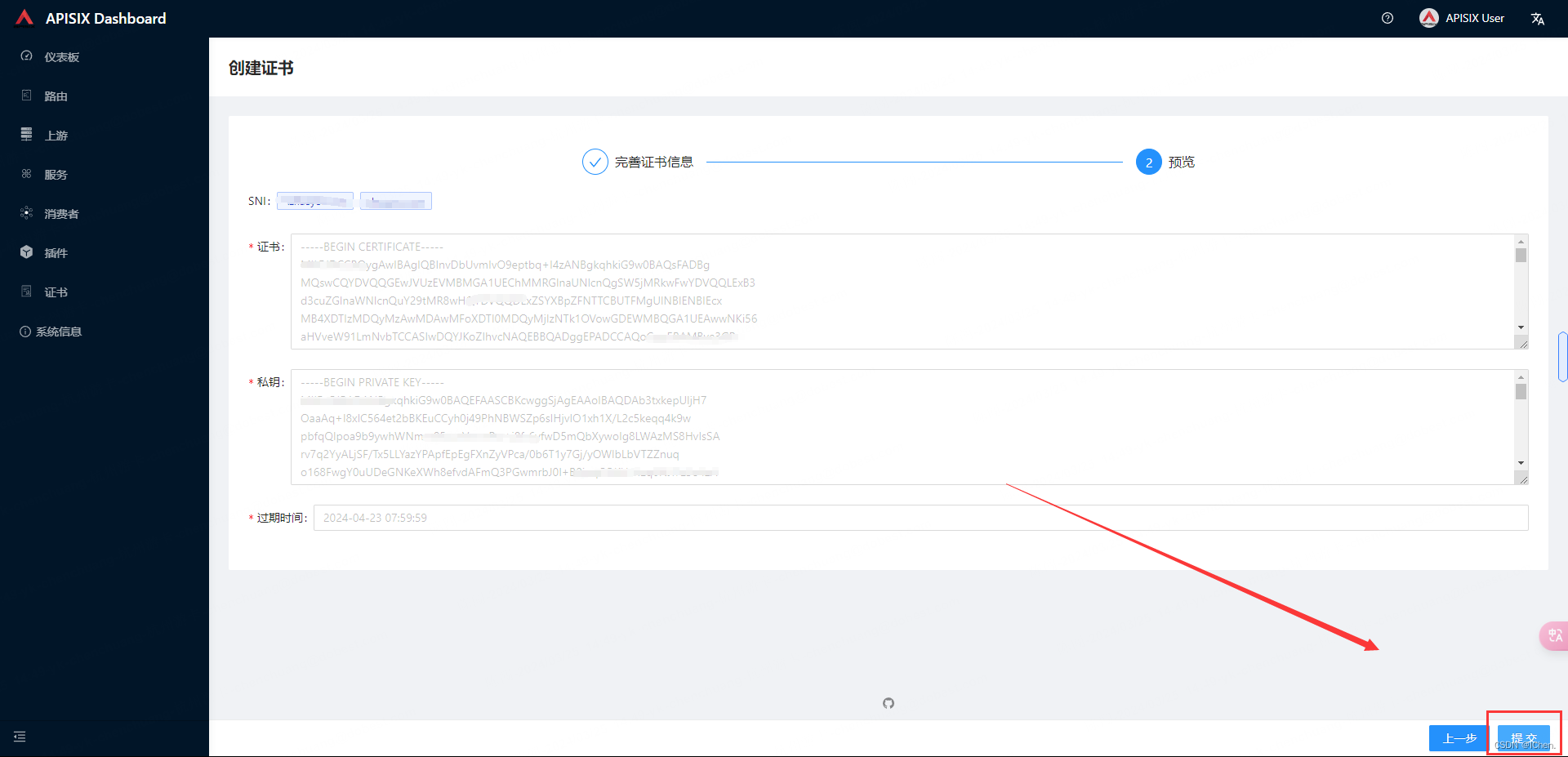
上传完证书之后不用做任何操作,就可以使用该域名的https了,因为apisix 自动匹配了域名和证书