jsp做网站实例梁定然网页设计教程
最近在测试Syslog udp发送相关功能,测试环境是centos
udp头部的数据长度是2个字节,最大传输长度理论上是65535,除去头部这些字节,可以大概的说是64k。
写了一个超过64k的数据(随便用了一个7w字节的buffer)发送demo,打印的是:Error: Message too long,sendto返回值是-1。接收端也没有收到
int UDPClient::Send(const char *buffer, int length)66 {67 if (mb_closed) {68 //HLog(HGET_ERROR<<L"soket was closed.");6970 return -1;71 }72 int i = sendto(mi_sock_fd, buffer, length, 0,73 (sockaddr *)&serverAddr, sizeof(serverAddr));7475 fprintf(stderr, "Error: %s\n", strerror(errno));76 return i;77 }而后又用了一个5w字节的buffer发送,这次发送是正常的
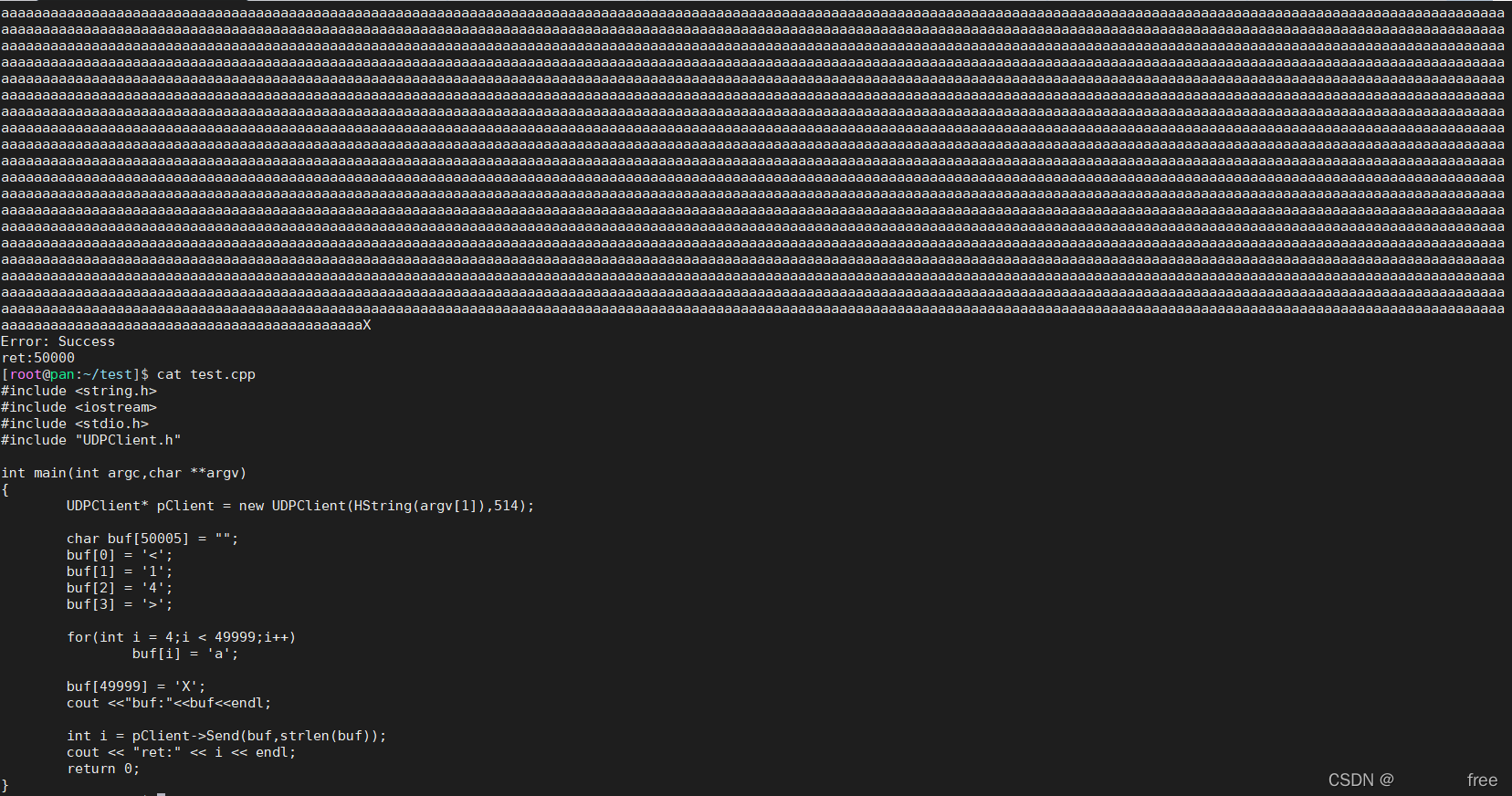
接收端开启的是linux自带的rsyslog服务,接收到的日志写入了/var/log/messages,查看文件接收到的数据长度也符合。

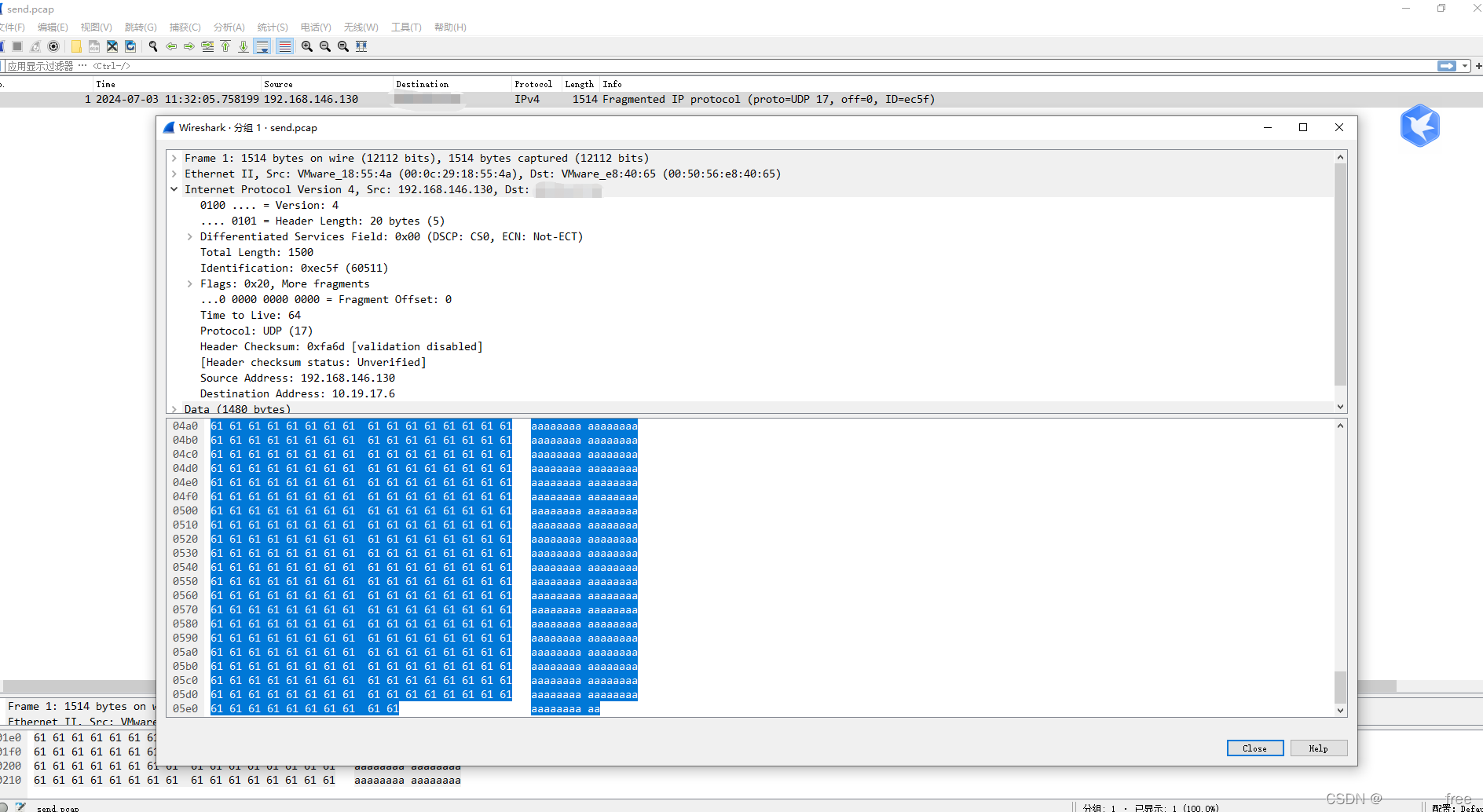
不过发送端和接收端双端抓包都只抓到一条,且长度不符合发送的长度5w,总共时一个mtu,大概可以知道只是抓到了一个分片,但是后序的包为什么抓不到呢
tcpdump -i ens192 -vvvv -s0 udp port 514
而后我们再StackOverflow上发现了:
That’s probably because whatever traffic is going to port 5201 consists of UDP packets that are larger than what would fit in a single link-layer packet, so IP has to fragment them.
That filter, unfortunately, will only capture the first fragment, because the OS filtering mechanism that libpcap uses does filtering on a packet-by-packet basis without maintaining any packet history, and either 1) the first fragment of a fragmented UDP packet will contain the full UDP header, and the others will not have any information to identify them as being additional fragments of that fragmented packet (without packet history, the IP identifier doesn’t help) or 2) the UDP header itself is fragmented, in which case the filter won’t work at all (that will probably never happen in practice, but it’s not ruled out by RFC 791). Additional fragments won’t be captured, so you won’t have the full packet.
意思是:当发送到端口的流量包含大于单个链路层数据包能够承载的UDP数据包时,IP层会将这些数据包进行分片处理。第一个UDP数据包的分片会包含完整的UDP头部,但后续的分片则不包含UDP头部。由于过滤机制是基于单个数据包进行的,且没有维护数据包历史,因此后续的分片在没有额外信息的情况下无法被识别为属于同一个原始UDP数据包的碎片。IP标识符虽然可以用于区分不同的分片是否属于同一个原始IP数据包,但它并不足以在没有额外上下文的情况下确定这些分片是否属于同一个UDP会话。
所以调整下抓包命令,去掉端口参数,发现可以抓到完整的包。
tcpdump -i ens192 -vvvv -s0 udp -w /tmp/20240703.pcap
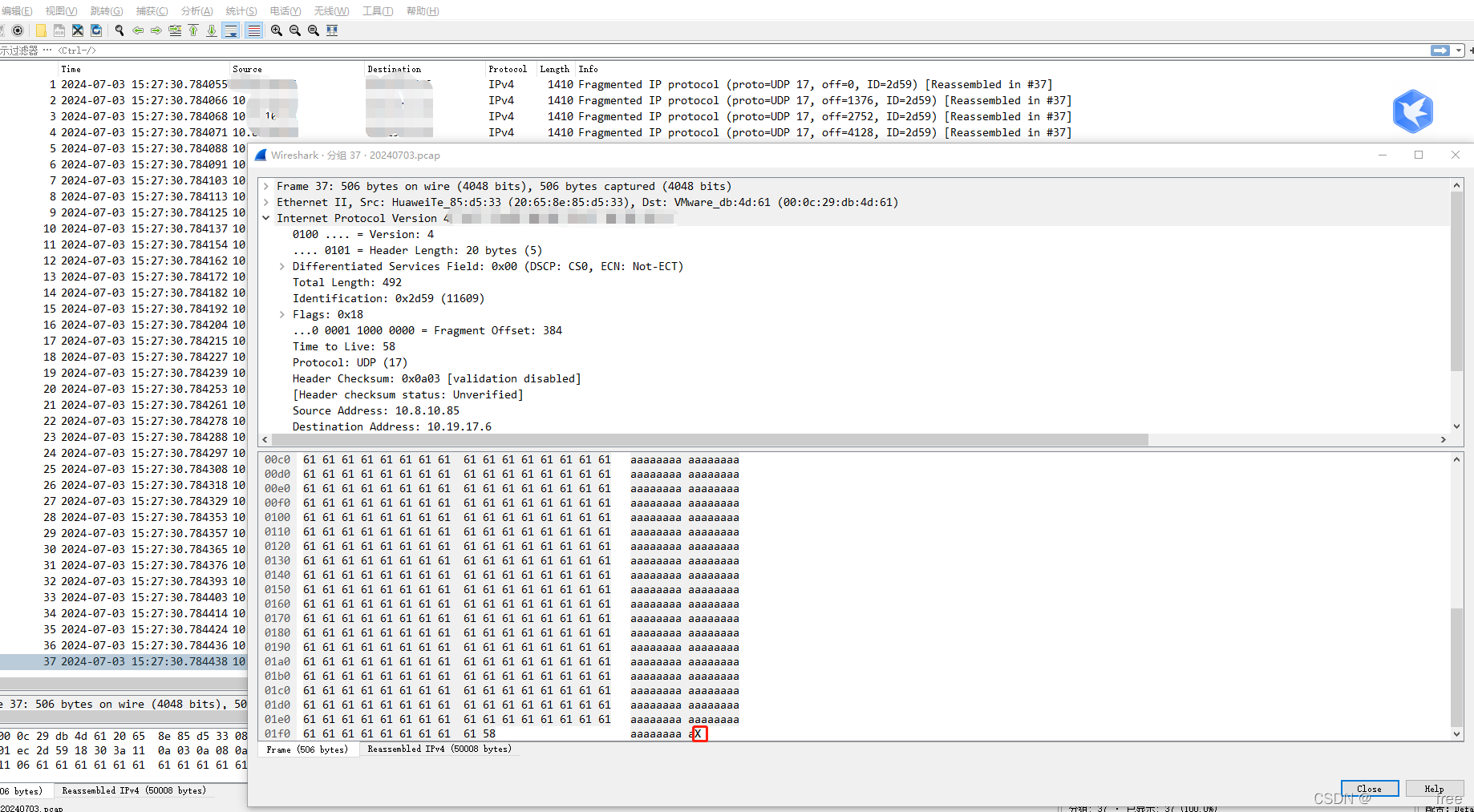
所以:udp发送超过64k(大概的数字,除去ip和udp头部长度),需要开发人员在应用层把消息分片,不然系统的发送接口sendto会报错(message too long),返回-1,发送失败,接收端收不到任何消息。
如果消息长度是64k以内,不需要开发人员在应用层分片,发送不会失败,但是单次最大长度是1500-头部,大概1400多,也就是会分片传多次,接收端会自行会重组数据的,但不会校验,如果在传输过程中有数据包丢失或损坏,接收端可能无法重组出完整的数据。接收端无法重组出完整的数据,那么这个包整个会被放弃,所以udp传输要么全部收到,要么全部收不到,没有收到一半的情况