深圳海外网站建设wordpress 输出the id
BC9 printf的返回值
这里我们先要了解库函数printf


printf的返回值,是写入的字符总数
我们第一遍写代码时候可能写成这样:
#include<stdio.h>
int main()
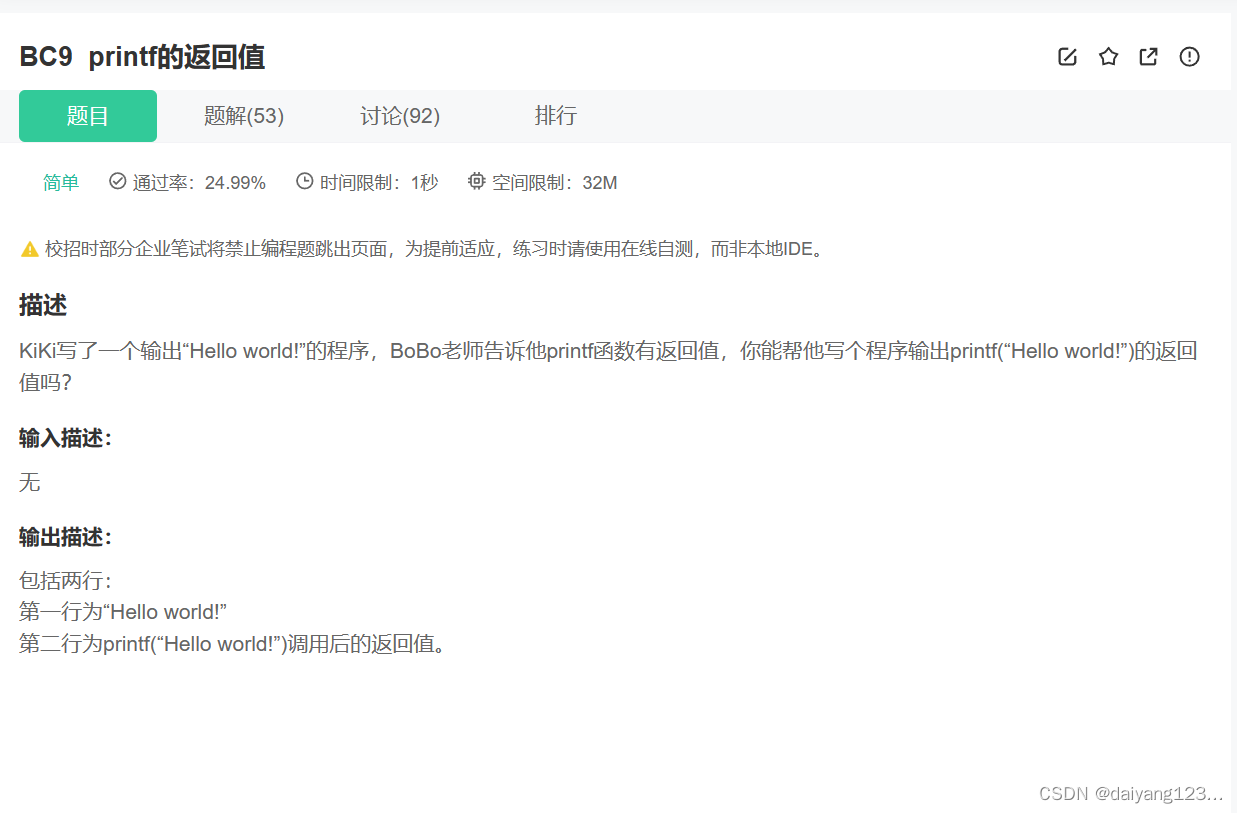
{int ret=printf("Hello world!");printf("%d", ret);return 0;
}
我们发现这样是通过不了测试的:
#include<stdio.h>
int main()
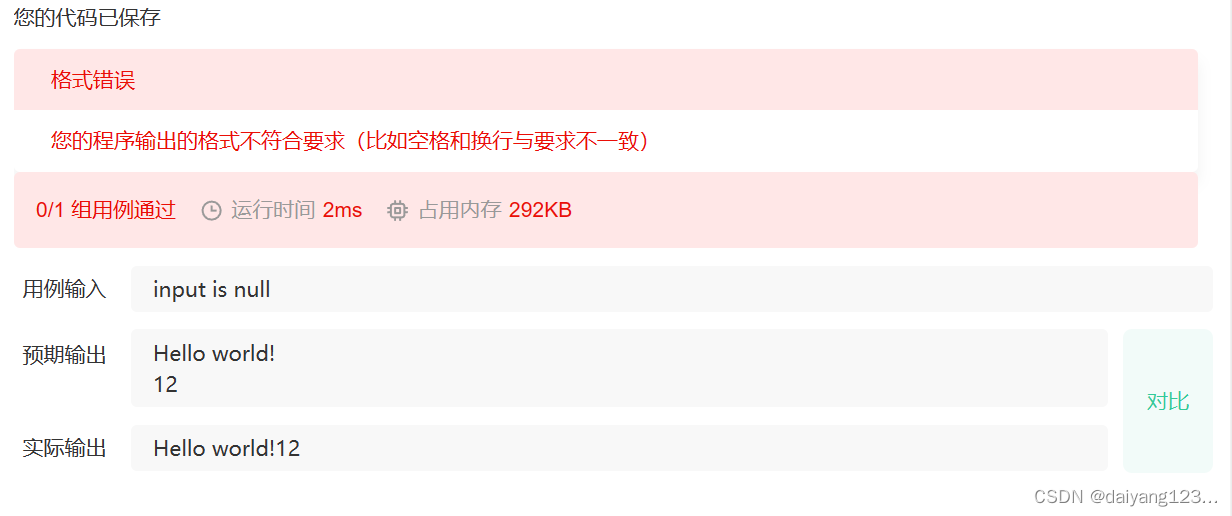
{int ret=printf("Hello world!\n");printf("%d", ret);return 0;
}
然后有的同学会直接给Hello world!后面加\n
结果还是通不过。因为\n也被当作字符算进返回值里面了。
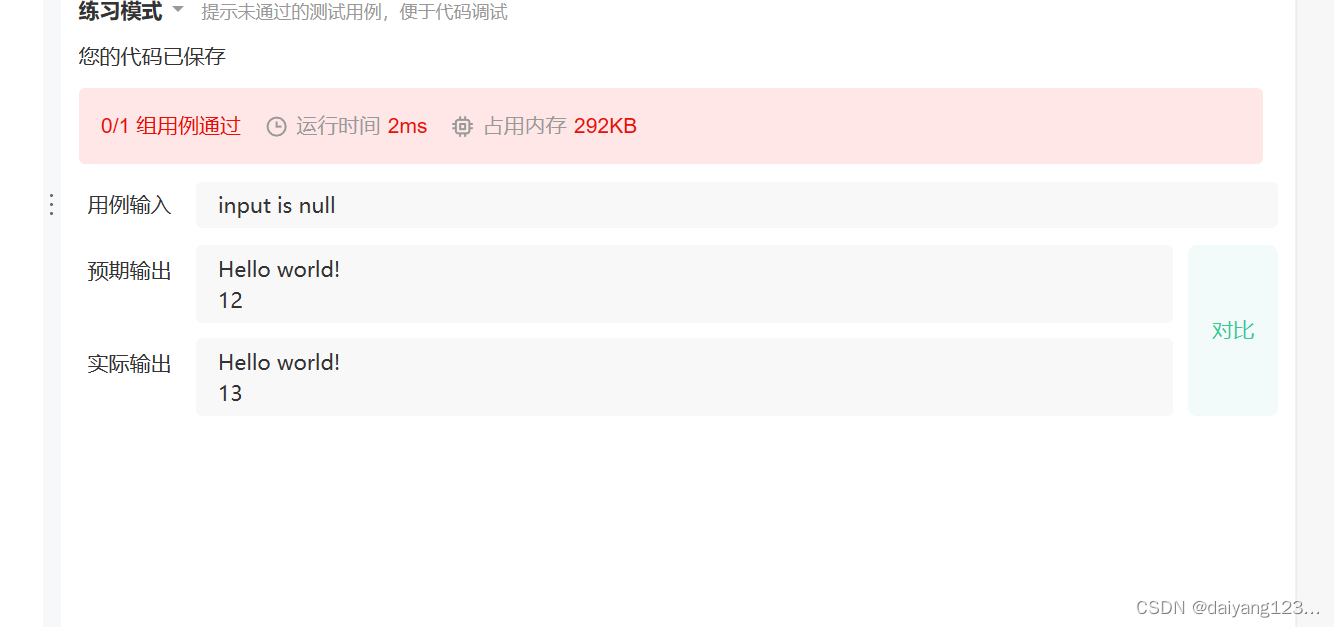
我们再次改进代码如下
#include<stdio.h>
int main()
{int ret=printf("Hello world!");printf("\n");printf("%d", ret);return 0;
}
我们再次改进:
#include<stdio.h>
int main()
{int ret=printf("Hello world!");printf("\n%d\n", ret);return 0;
}
我们如果只想用一个printf语句呢
#include<stdio.h>
int main()
{printf("%d", printf("Hello world!"));return 0;
}