江苏初中课程基地建设网站方庄网站制作
文章目录
- 1. 引言
- 2. 实验原理
- 2.1 散列表
- 2.2 线性探测法
- 3. 实验内容
- 3.1 实验题目
- (一)输入要求
- (二)输出要求
- 3.2 算法实现
- 三、实验设计
- 3.3 代码整合
- 4. 实验结果
1. 引言
本实验将通过C语言实现基于线性探测法的散列表
2. 实验原理
2.1 散列表
散列表(Hash Table)是一种常用的数据结构,用于快速存储和查找数据。在散列表中,通过散列函数将关键字映射到一个索引位置,然后将数据存储在该位置上。然而,由于不同的关键字可能映射到相同的索引位置,就会发生散列冲突。线性探测法是一种解决冲突的方法,它在发生冲突时,顺序地检查下一个位置,直到找到一个空闲的位置或者遍历完整个散列表。
2.2 线性探测法
基于线性探测法的散列表查找是一种解决散列冲突(Hash Collision)的方法之一。具体的线性探测法查找过程如下:
- 根据关键字计算散列值,得到初始的索引位置。
- 如果该位置为空,表示没有发生冲突,查找失败,返回结果。
- 如果该位置不为空,比较关键字是否匹配,如果匹配,则查找成功,返回结果。
- 如果不匹配,则继续检查下一个位置(通过线性探测法的方式,即加1),直到找到一个空闲位置或者遍历完整个散列表。
- 如果找到空闲位置,表示查找失败,返回结果。
- 如果遍历完整个散列表,表示查找失败,返回结果。
需要注意的是,线性探测法可能会导致聚集(Clustering)现象,即相邻的位置都被占用,导致查找效率下降。为了解决这个问题,可以采用其他的解决冲突方法,如链表法(Chaining)或二次探测法(Quadratic Probing)。
3. 实验内容
3.1 实验题目
编写算法构造教材图 8.47 的拉链表,输出散列表每个槽对应的单链表,并编程计算查找成功时的平均查找长度。
(一)输入要求
char *A[30]={"THE","OF","AND","TO","A","IN","THAT","IS","WAS","HE","FOR","IT","WITH","AS","HIS","ON","BE","AT","BY","I","THIS","HAD","NOT","ARE","BUT","FROM","OR","HAVE","AN","THEY",};
- 散列函数自选。
(二)输出要求
- 输出散列表,空位输出“NULL”;
- 编程计算并输出查找成功时的平均查找长度。
3.2 算法实现
三、实验设计
-
散列表数组:
char *TABLE[31] = { "\0" };数组
TABLE,包含 31 个元素,每个元素是一个字符串指针。 -
插入函数
L:void L(char *TABLE[31], char *K, int M) {int i = B[N];while (TABLE[i]){sum++;if (strcmp(TABLE[i], K) == 0)return;i = (i + 1) % M;}if (N < M - 1){TABLE[i] = K;N++;return;}return; }插入函数
L用于在散列表中插入数据。当发生冲突时,使用线性探测法沿着数组查找下一个可用的位置。 -
主函数:
int main(){char *A[30] = { /* ... */ };char *TABLE[31] = { "\0" };int i;for (i = 0; i < 30; i++){L(TABLE, A[i], 31);}for (i = 0; i < 31; i++){if (TABLE[i])printf("%d:%s\n", i, TABLE[i]);elseprintf("%d:NULL\n", i);}N = 0;sum = 0;for (i = 0; i < 30; i++){L(TABLE, A[i], 31);N++;}printf("\n平均查找长度为%f", (float)sum / 30); }
3.3 代码整合
#include<stdio.h>
#include<string.h>
int B[31]={25,9,11,27,1,7,9,26,5,13,27,29,2,18,18,1,7,21,27,9,6,13,21,22,3,22,29,26,15,0
};
int sum=0,N=0;
void L(char *TABLE[31],char *K,int M)
{int i=B[N];while(TABLE[i]){sum++;if(TABLE[i]==K) return;i=(i+1)%M;}if(N<M-1){TABLE[i]=K;N++;return;}return;
}
int main(){char *A[30]={"THE","OF","AND","TO","A","IN","THAT","IS","WAS","HE","FOR","IT","WITH","AS","HIS","ON","BE","AT","BY","I","THIS","HAD","NOT","ARE","BUT","FROM","OR","HAVE","AN","THEY",};char *TABLE[31]={"\0"};int i;for(i=0;i<30;i++){L(TABLE,A[i],31);}for(i=0;i<31;i++){if(TABLE[i])printf("%d:%s\n",i,TABLE[i]);elseprintf("%d:NULL\n",i);}N=0;sum=0;for(i=0;i<30;i++){L(TABLE,A[i],31);N++;}printf("\n平均查找长度为%f",(float)sum/30);
}4. 实验结果
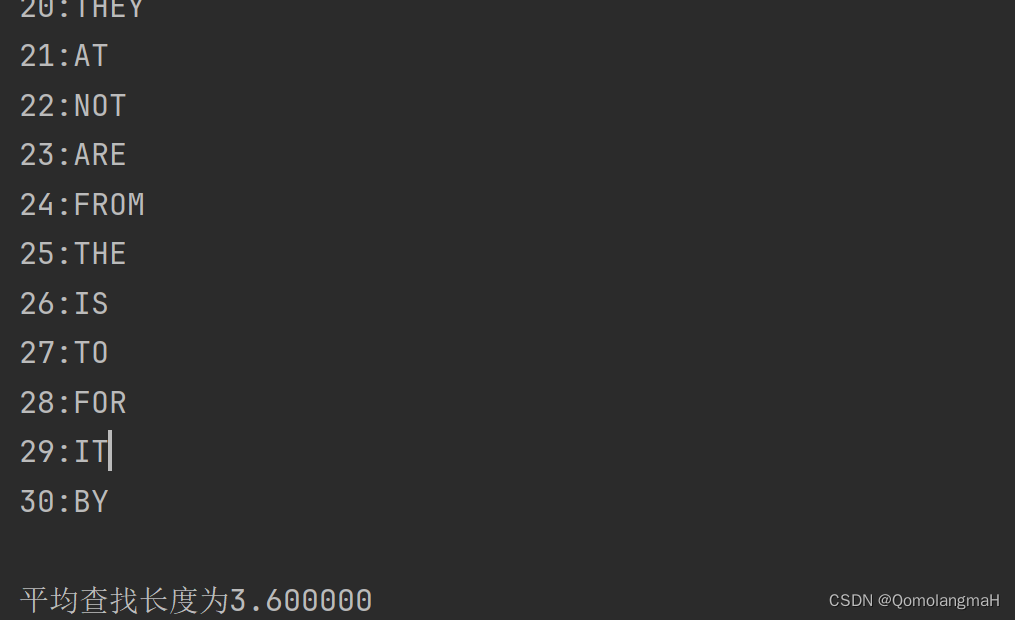
中序遍历:
0:
1:A
2:WITH
3:ON
4:BUT
5:WAS
6:THIS
7:IN
8:BE
9:OF
10:THAT
11:AND
12:I
13:HE
14:HAD
15:OR
16:HAVE
17:AN
18:AS
19:HIS
20:THEY
21:AT
22:NOT
23:ARE
24:FROM
25:THE
26:IS
27:TO
28:FOR
29:IT
30:BY平均查找长度为3.600000