河南制作网站高质量的邯郸网站建设
声明:
该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关
一、Akamai简介
Akamai是一家提供内容传递网络(CDN)和云服务的公司。CDN通过将内容分发到全球各地的服务器,以减少网络延迟并提高用户访问网站的速度和性能。在其服务中,Akamai使用一种称为Akamai Cookie加密的技术来增强安全性和保护用户的隐私。
Akamai常见的时1.75和2的版本, 传递的数据是明文的数据就是1.75,2版本的数据是进行编码的
二、Akamai特点
- 请求网页地址,网页地址会返回一个外链的js代码
- 对外链地址发送get请求,获取到对应的js代码
- 在对当前外链js地址发送post请求,带上参数sensor_data
- 带上参数请求之后,会响应一个正确的_abck,1的版本基本就只有_abck,2的版本的有bm_sv 、bm_sz
- 逆向参数时需要注意Akamai,每周会有一小改,一个月会大改一次,有网站会提供破解接口:https://sb-ai.atlassian.net/wiki/spaces/A/overview
- 最重要的就是第二次的post请求,逆向的参数是sensor_data
三、akamai cookie分析
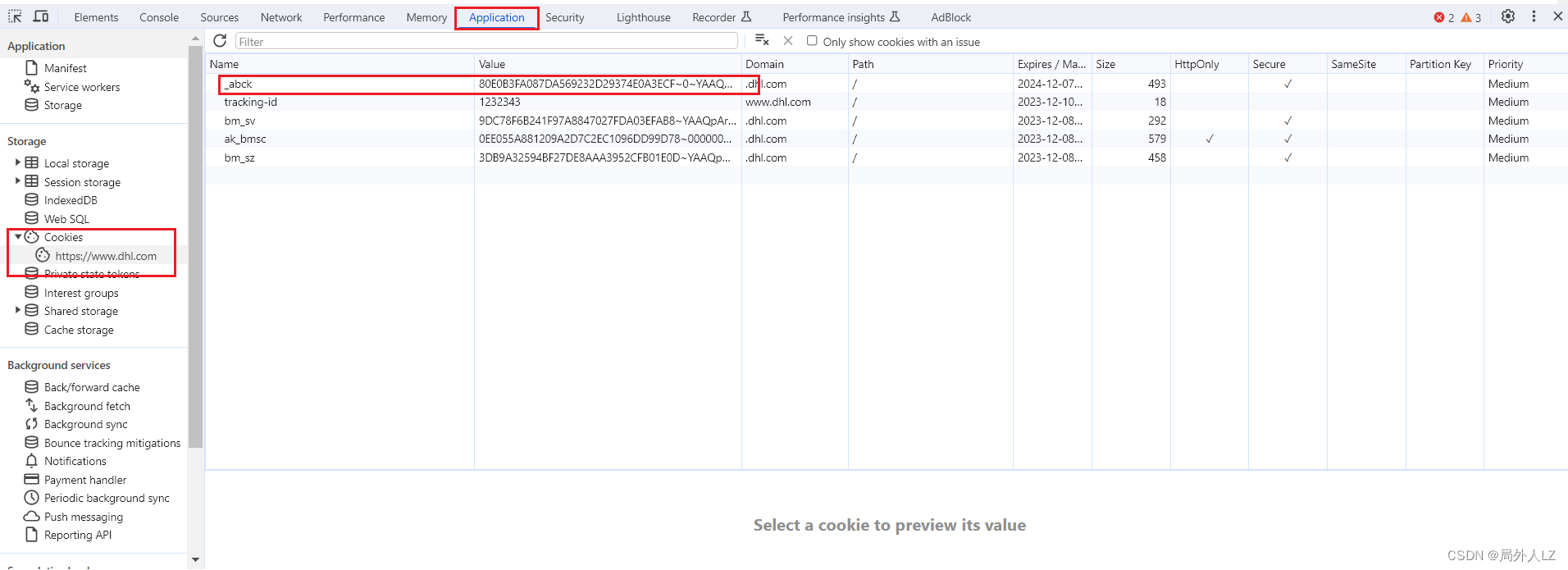
- js运行atob(‘aHR0cHM6Ly93d3cuZGhsLmNvbS9jbi16aC9ob21lL3RyYWNraW5nL3RyYWNraW5nLWVjb21tZXJjZS5odG1sP3N1Ym1pdD0xJnRyYWNraW5nLWlkPTEyMzIzNDM=’) 拿到网址,打开网页,F12打开调试工具,切换到Application,找到cookie,会发现_abck,说明该网站是akamai加密
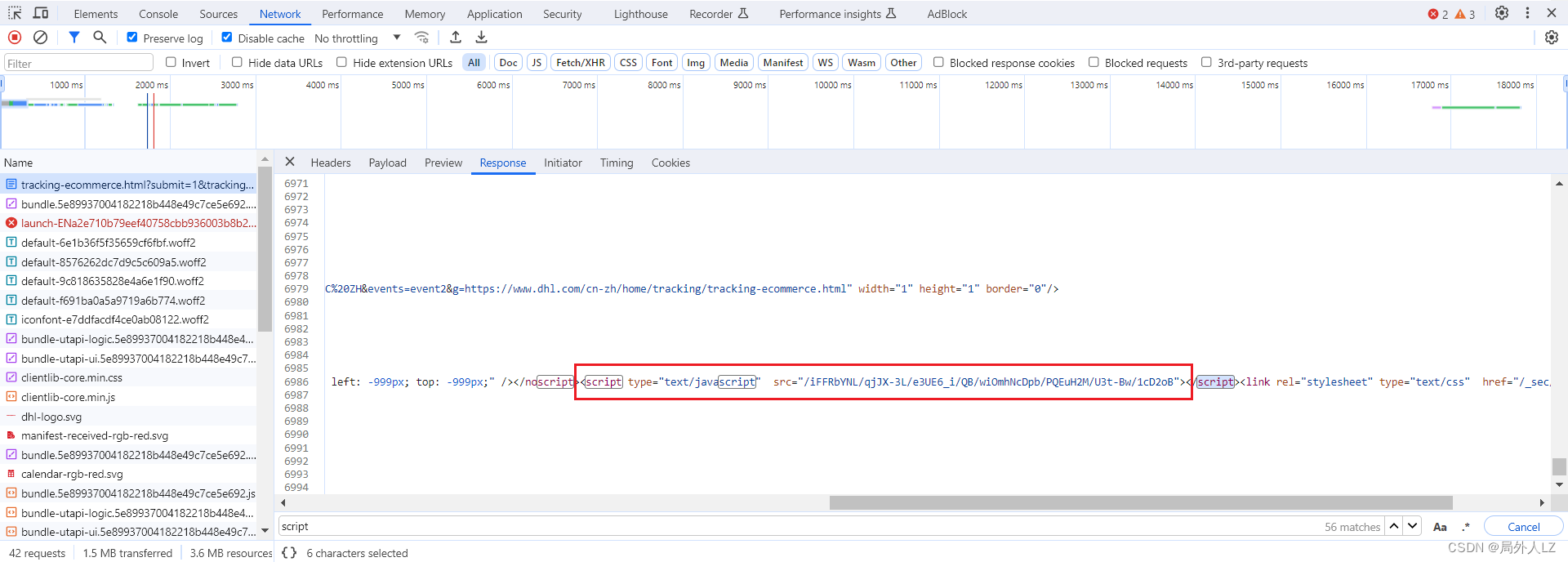
- 清除cookie,刷新页面,切换到Network,首先分析tracking/tracking-ecommerce.html请求,响应返回一个html,里面有个外链js,后面会对这个外链js发送两次请求
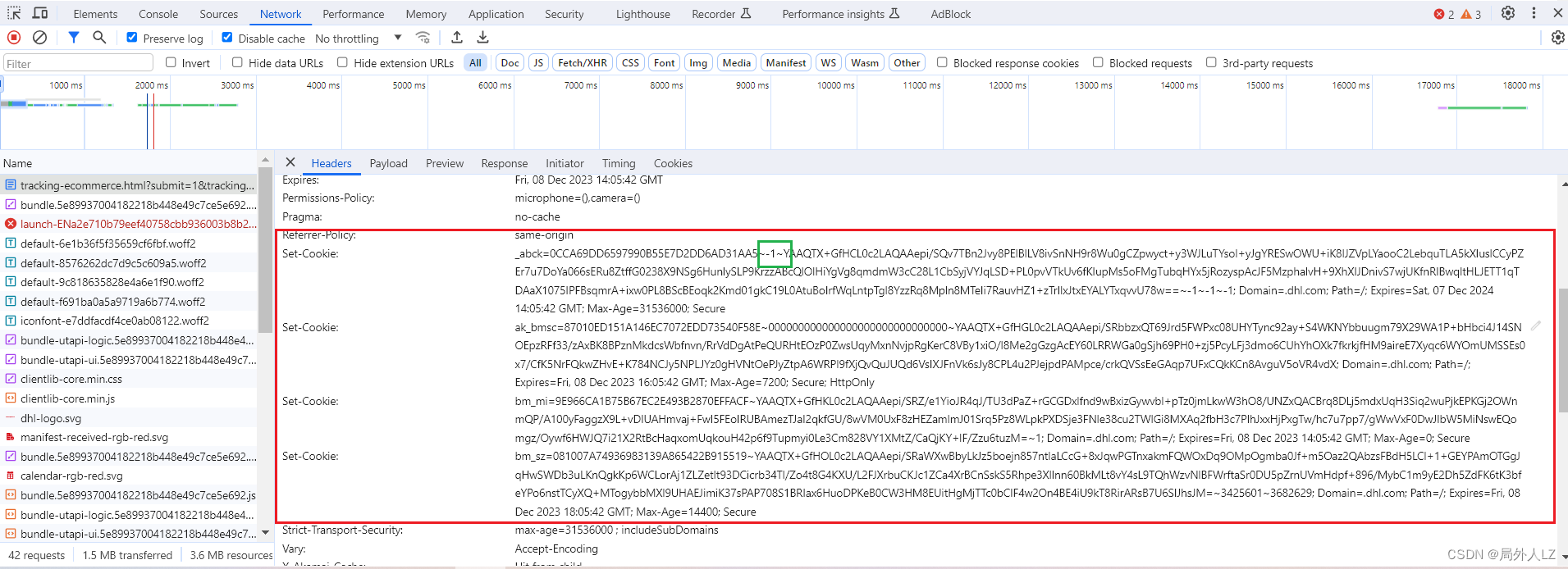
- 第一次请求外链js,会根据tracking/tracking-ecommerce.html中响应的cookie,拿到js,用于生成sensor_data,该cookie中有个_abck,但是这个_abck是不能用于请求其他数据的,注意看该值中间的 -1,这个-1说明是需要根据_abck再次请求才能拿到_abck
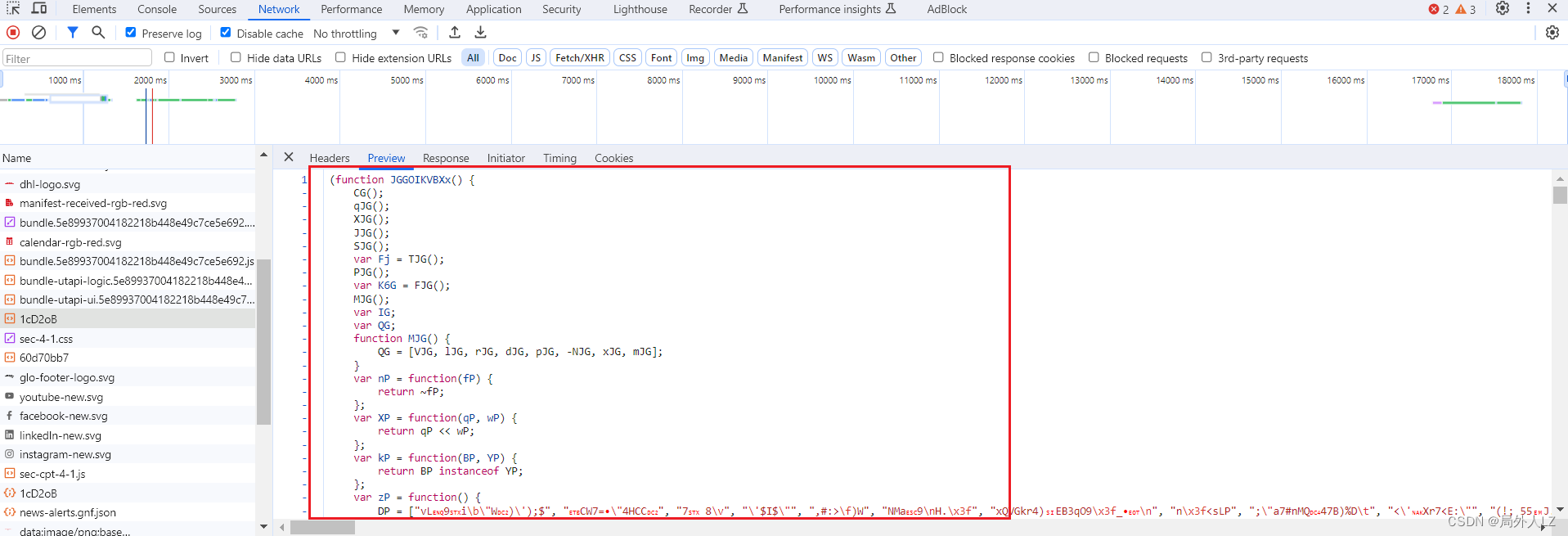
- 第二次请求,会使用生成的sensor_data,会拿到真正的_abck
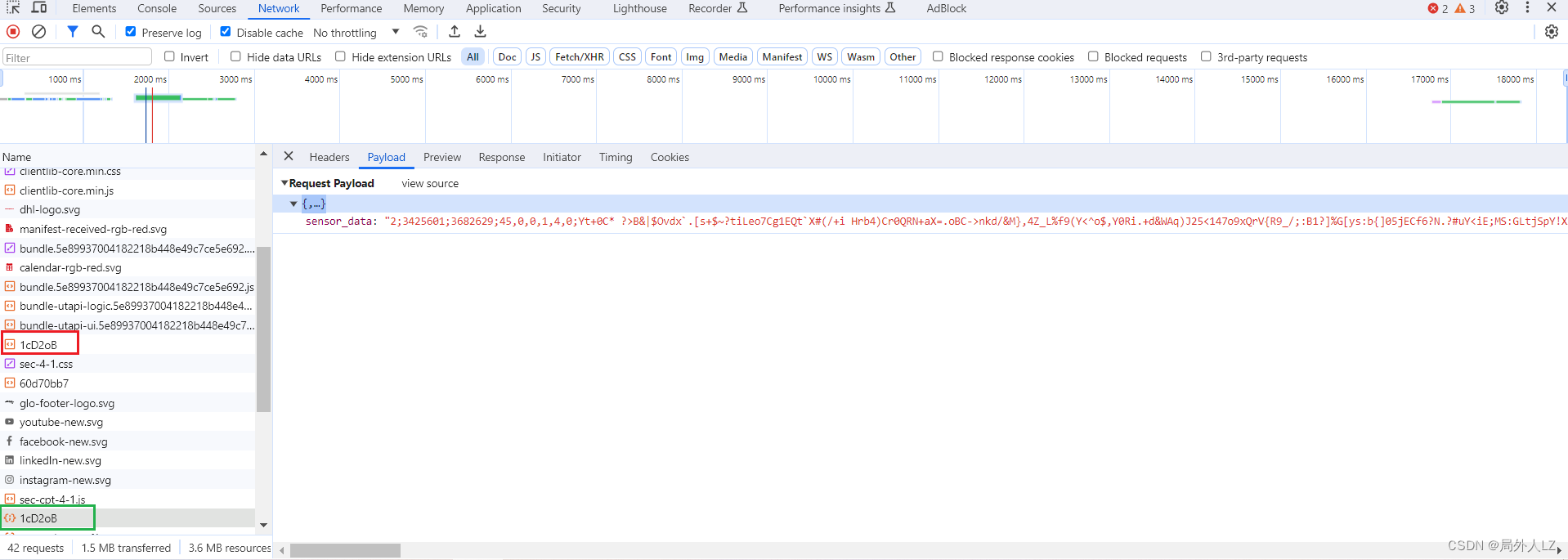
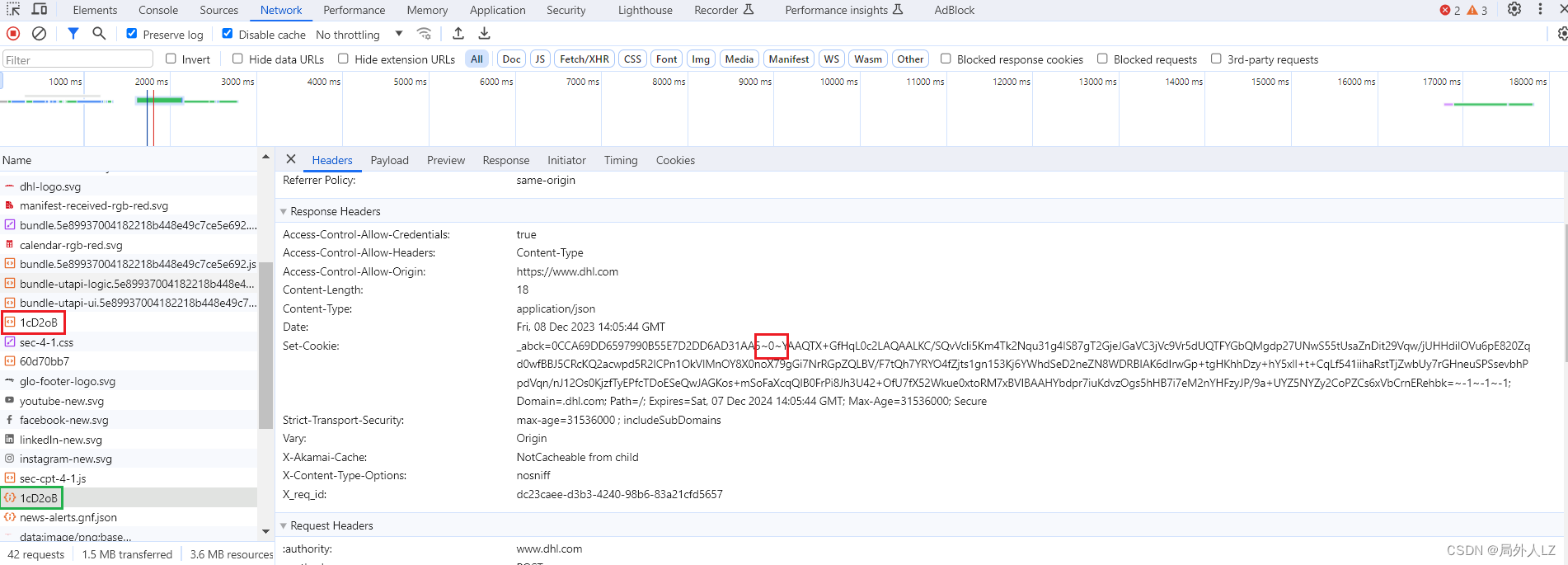
- 创建dhl.py,根据之前分析,完成前两次请求的代码
import requests
import reheaders = {'authority': 'www.dhl.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'no-cache','pragma': 'no-cache','sec-ch-ua': '\'Not_A Brand\';v=\'8\', \'Chromium\';v=\'120\', \'Google Chrome\';v=\'120\'','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '\'Windows\'','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}cookies = {}request_session = requests.session()
request_session.headers.update(headers)
request_session.cookies.update(cookies)url = 'https://www.dhl.com/cn-zh/home/tracking/tracking-ecommerce.html'
params = {'submit': '1','tracking-id': '1232343'
}
response = request_session.get(url,params=params)#更新cookie,这里不用设置也行,request_session会话对象,会保持上一个请求的信息,为了更直观一些,这里再设置以下
cookies['_abck'] = response.cookies['_abck']
cookies['ak_bmsc'] = response.cookies['ak_bmsc']
cookies['bm_sz'] = response.cookies['bm_sz']
request_session.cookies.update(cookies)js_path = re.findall('</noscript><script type="text/javascript" src="(.*?)"></script><link',response.text) #使用正则拿到外链js路径
js_url = f'https://www.dhl.com/{js_path[0]}'
response_js = request_session.get(js_url)print(response_js.text)
print(response_js)
四、分析sensor_data
- 使用无痕浏览器打开网站,为了方便调试,把html文件本地替换一下,这样能保证每次请求的js都是一样的
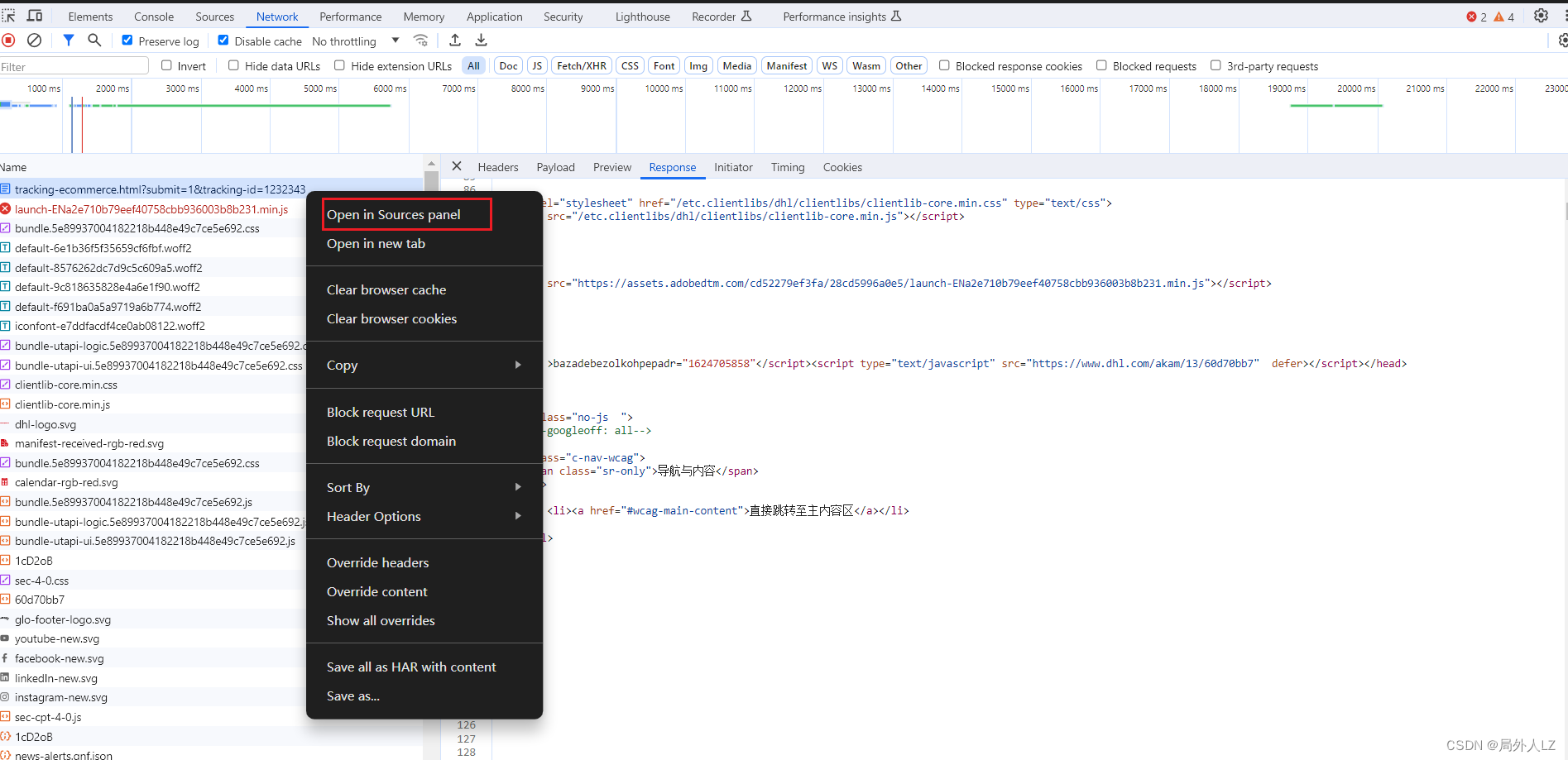
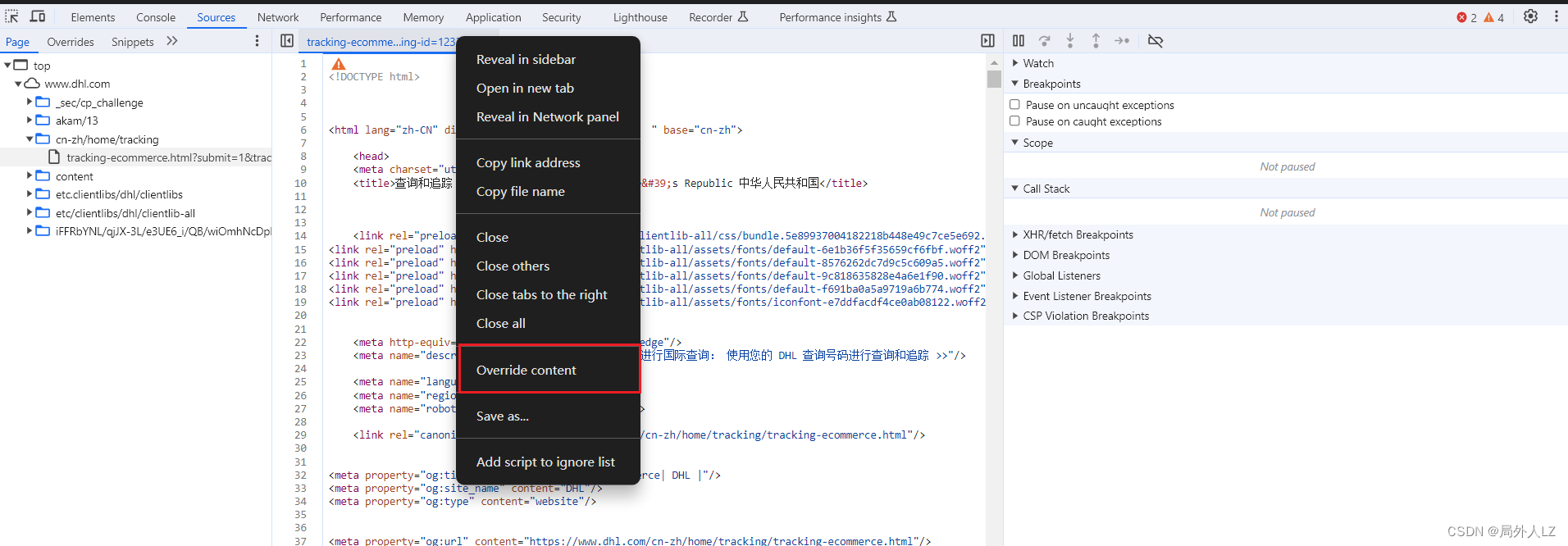
- 通过xhr拦截外链js的请求

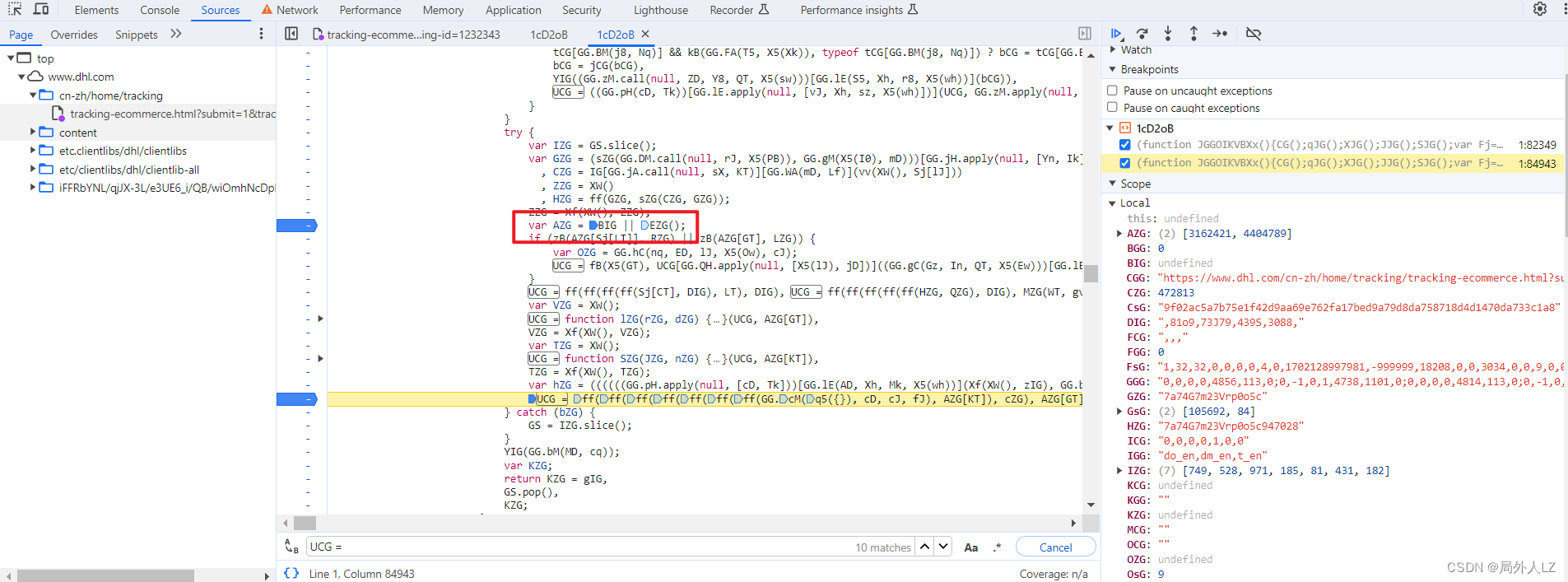
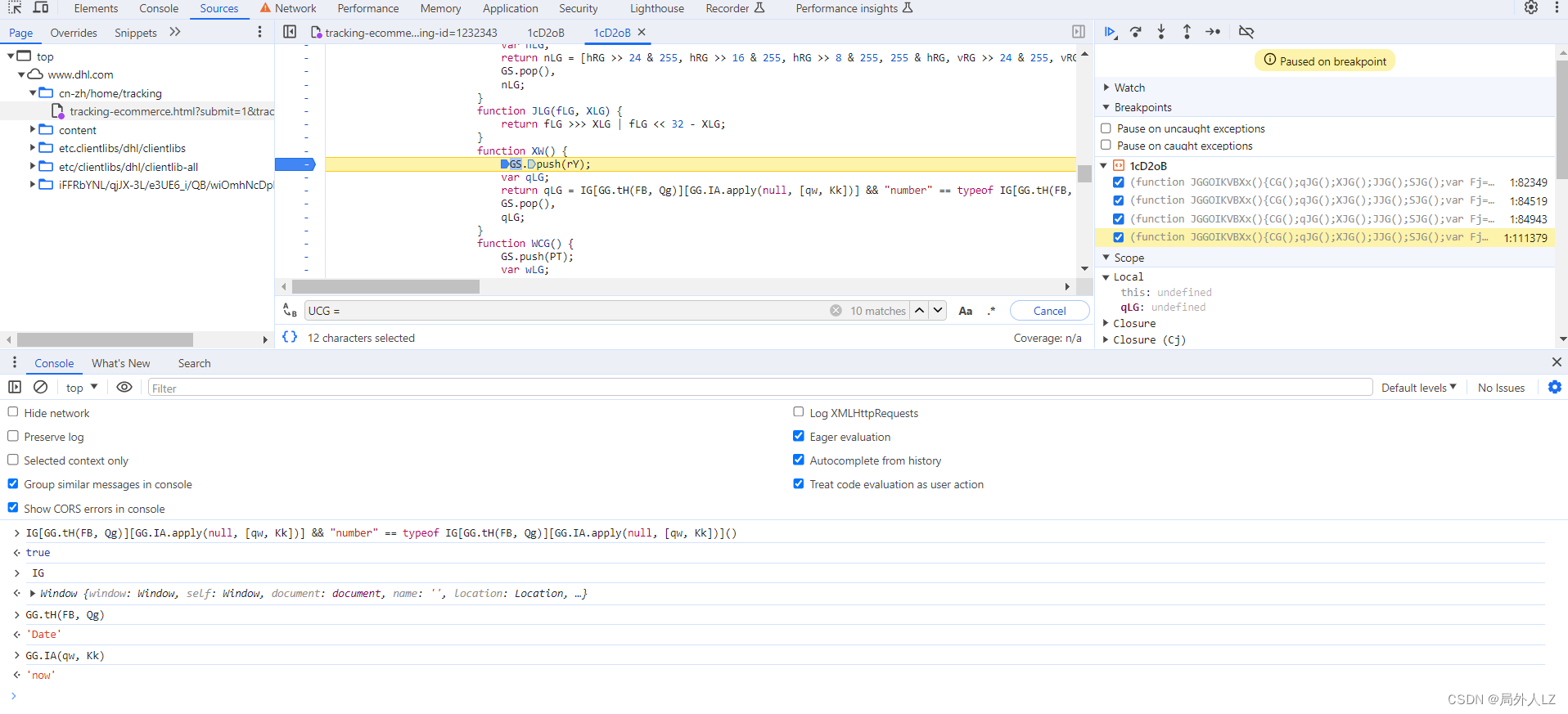
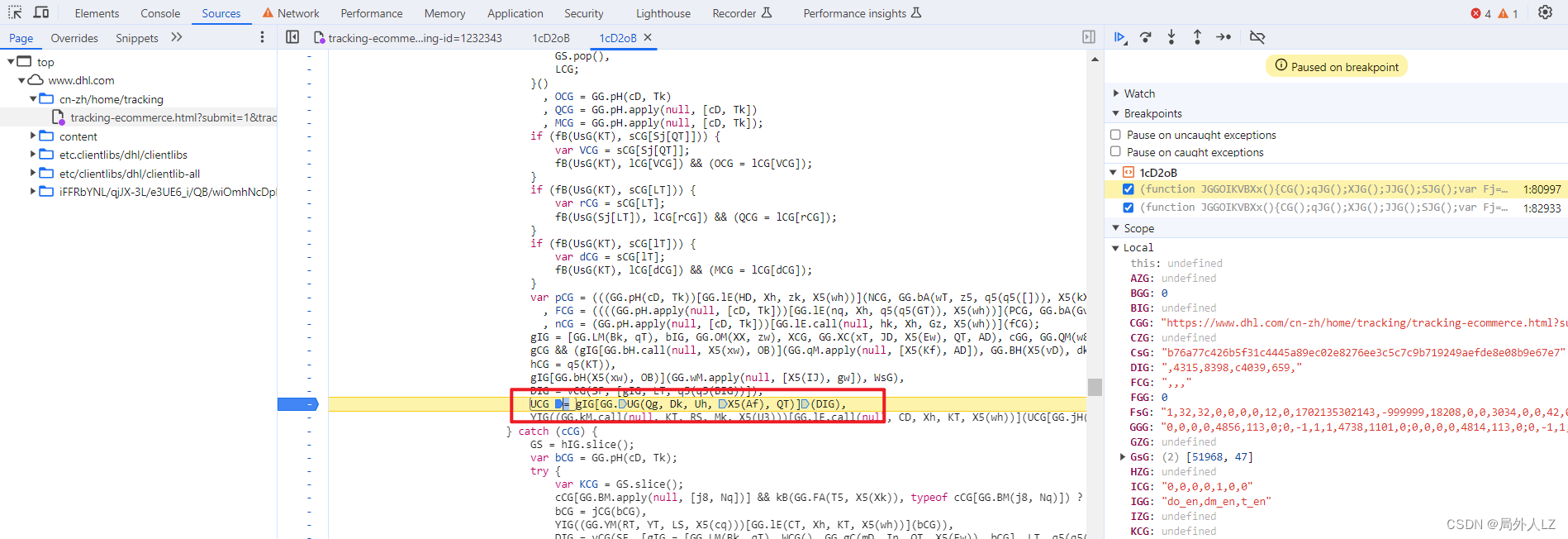
- 清除cookie,刷新页面,会进入刚才的断点,分析作用域能看到Y4G是发送请求的对象,z4G是发送请求的参数,里面有sensor_data,分析z4G赋值的地方,会发现有个UCG,把z4G、UCG在控制台输出,会发现UCG才是sensor_data的值
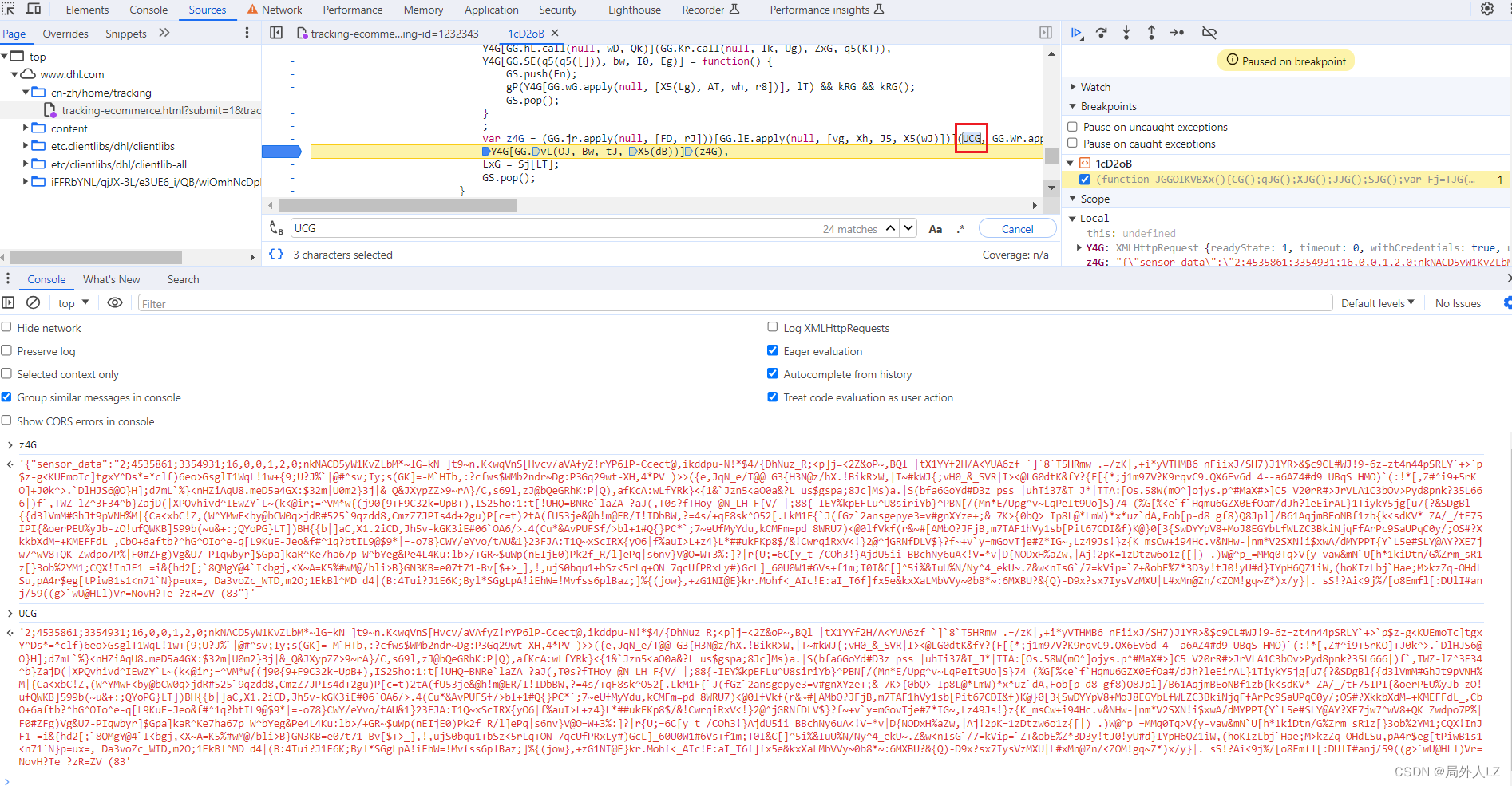
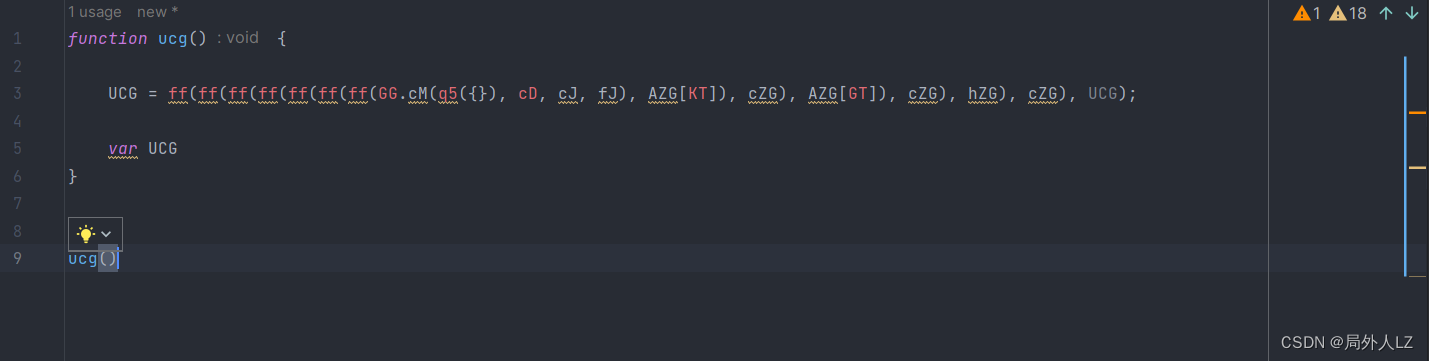
- 再文件内搜索UCG = ,在搜到的地方全部打断点,刷新页面,点击跳过断点,直到找到z4G的上一个赋值的上一个断点,找到断点记住断点位置1:84943,再刷新页面,找到刚才的断点,输出UCG的值,然后找到z4G断点,输出UCG的值对比两个值发现是一样的,说明UCG生成的位置就是在刚才的断点 1:84943,删除其他的断点,把UCG赋值的代码拷贝到dhl.js
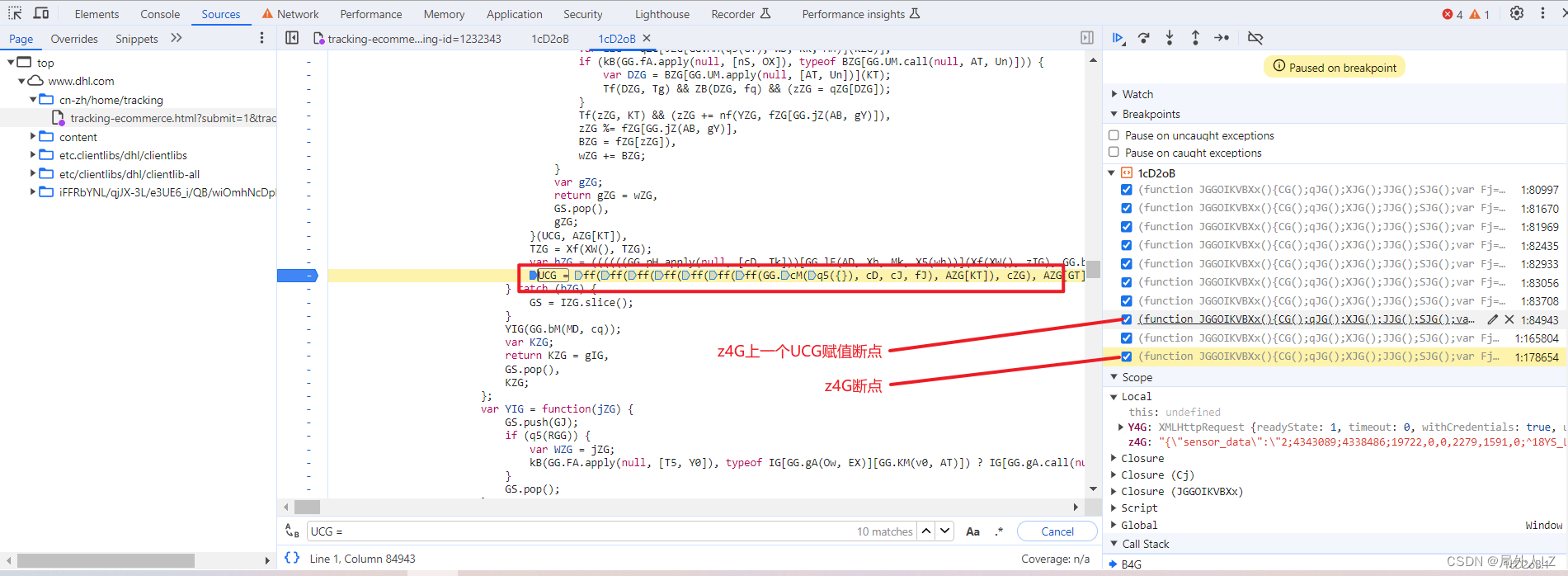
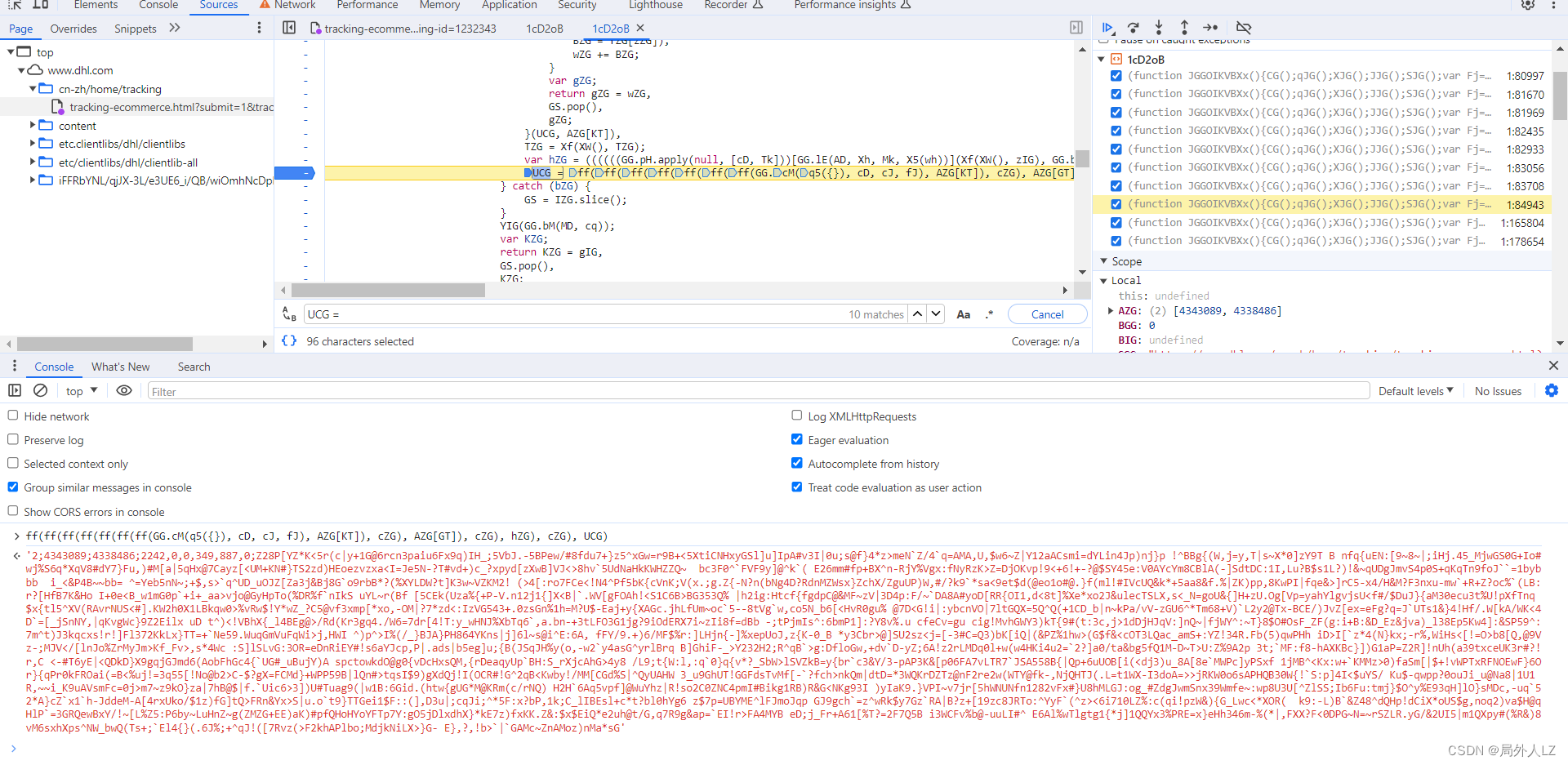
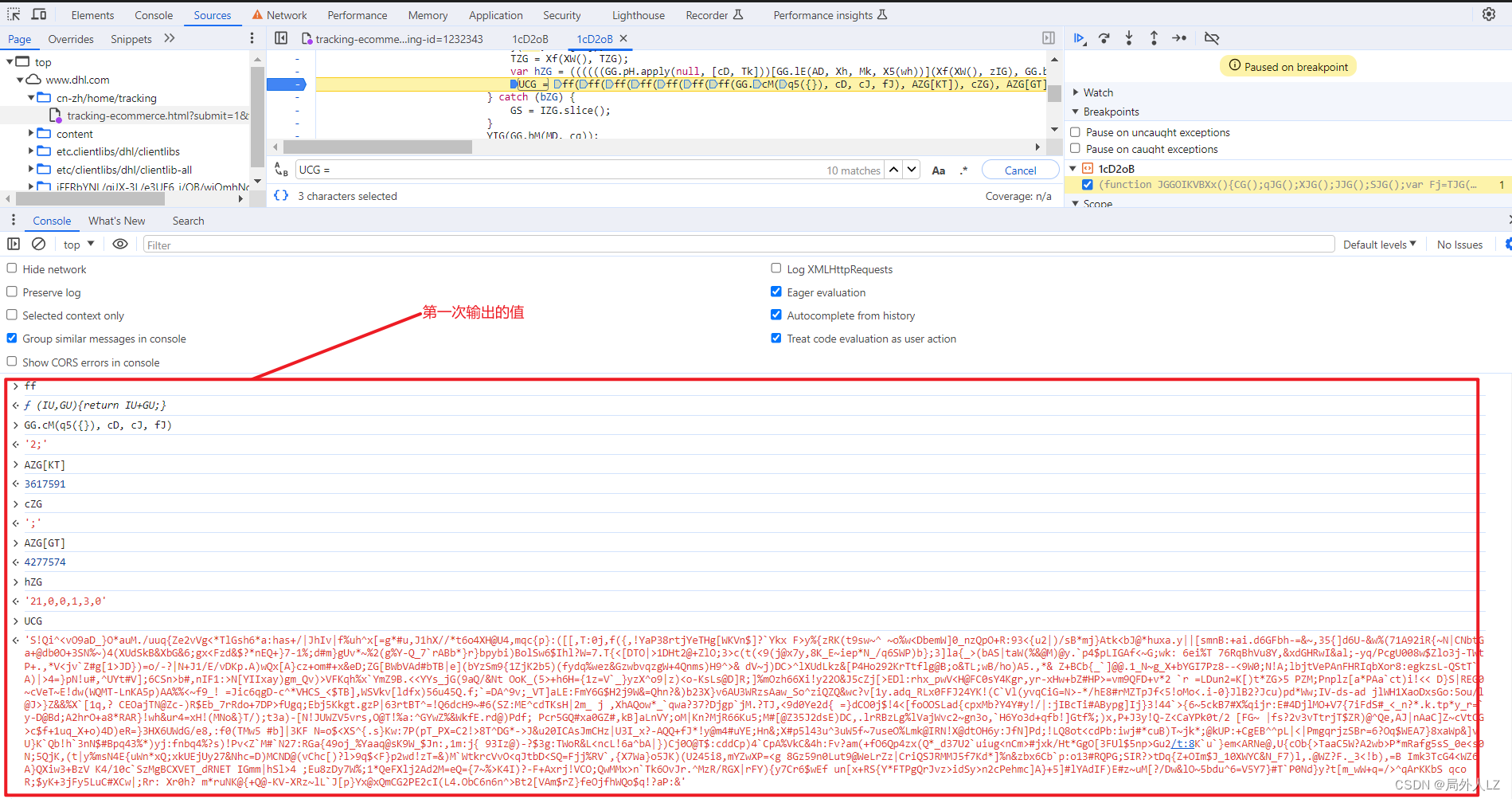
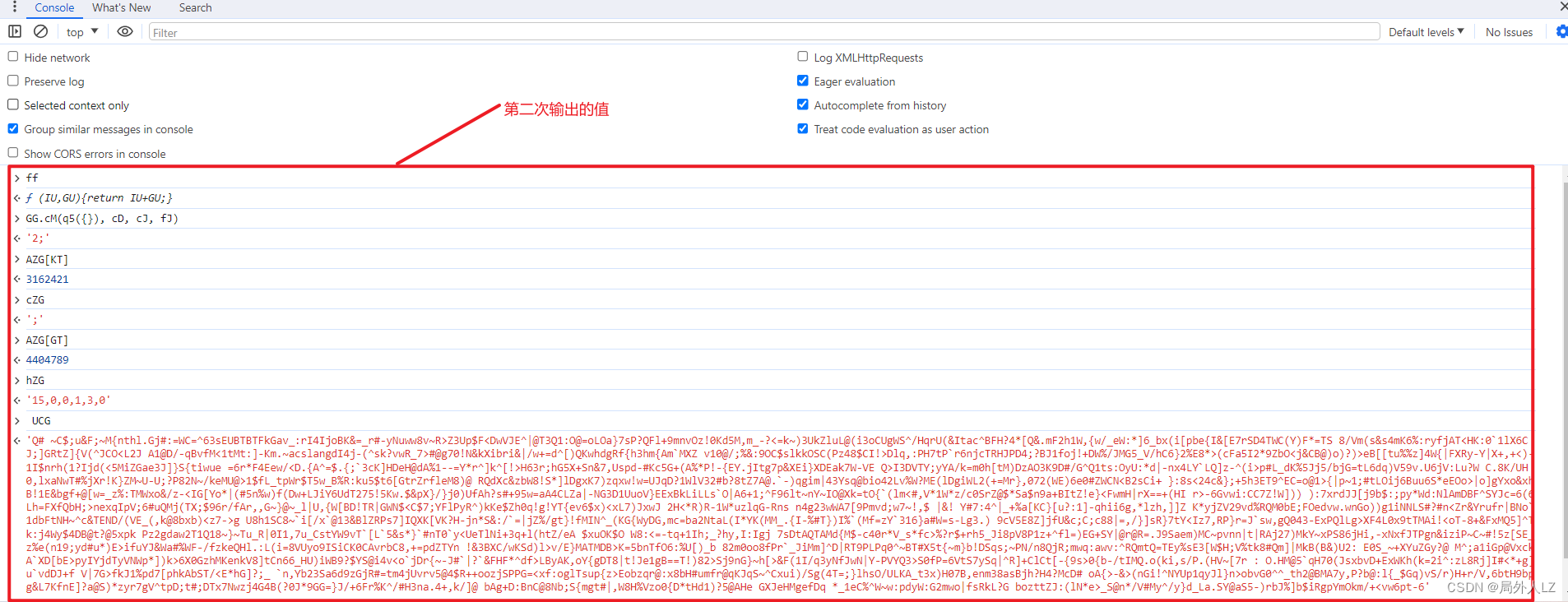
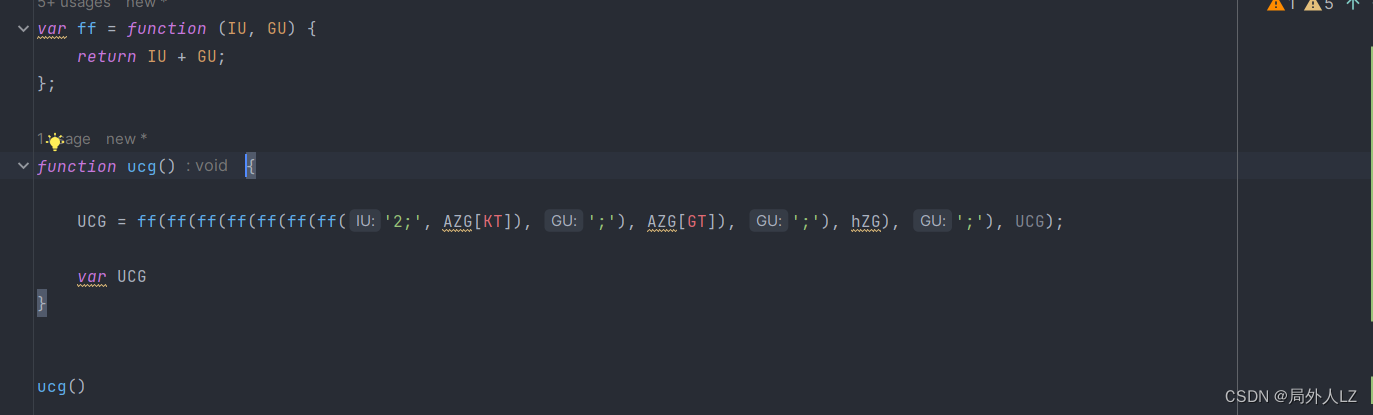
- 清除cookie,刷新页面,会跳到1:84943的断点位置,分析UCG代码赋值的地方,鼠标悬浮到变量上,是固定值得把值拷到dhl.js,非固定值的再做分析,把相关参数在控制台输出,然后,再刷新页面,再把相关的参数在控制台输出,对比两次结果,就能分析出哪些是固定值哪些是非固定值,对比两次结果会发现GG.cM(q5({}), cD, cJ, fJ)、cZG是固定值,ff是方法,其他是非固定值,先把ff、GG.cM(q5({}), cD, cJ, fJ)、cZG代码复制到dhl.js
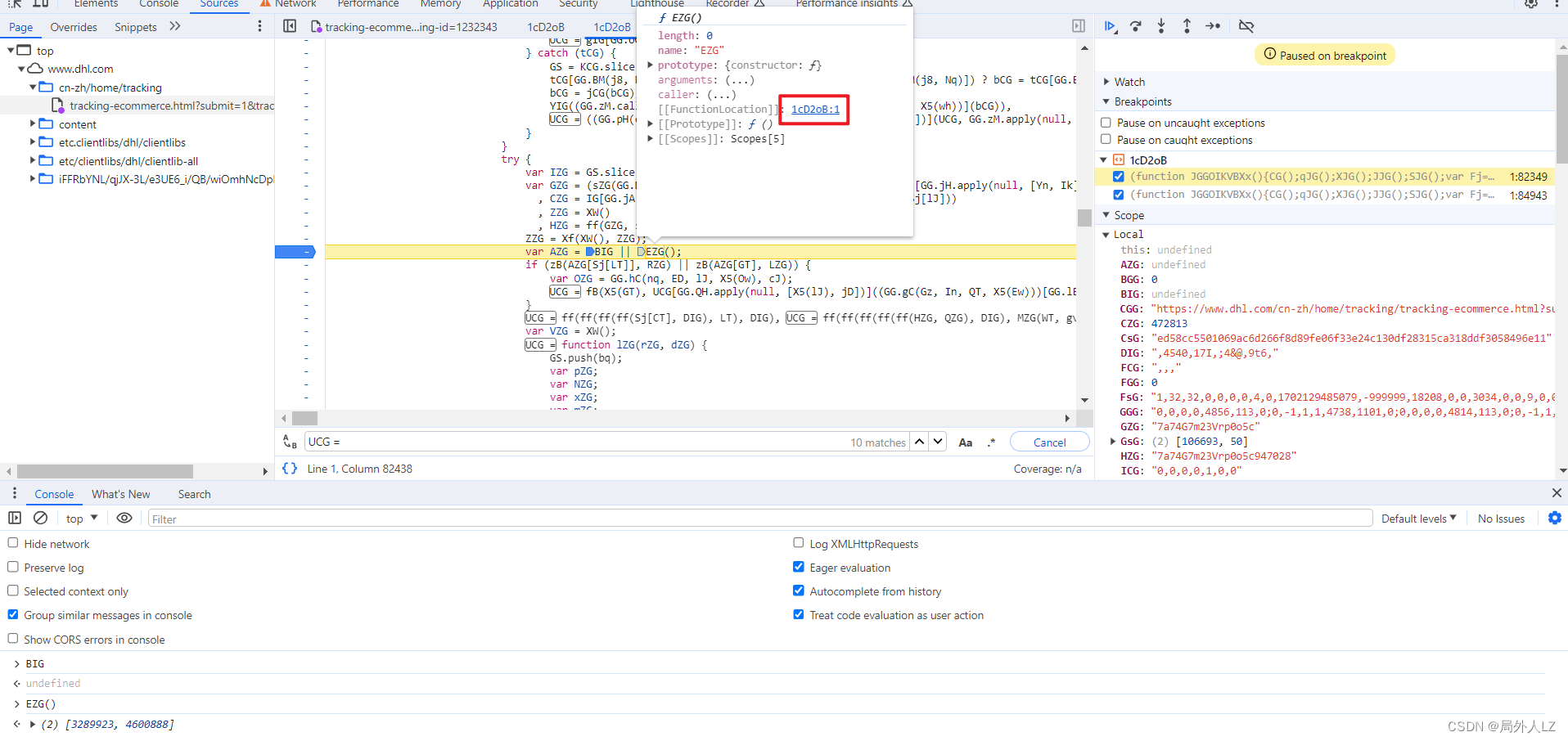
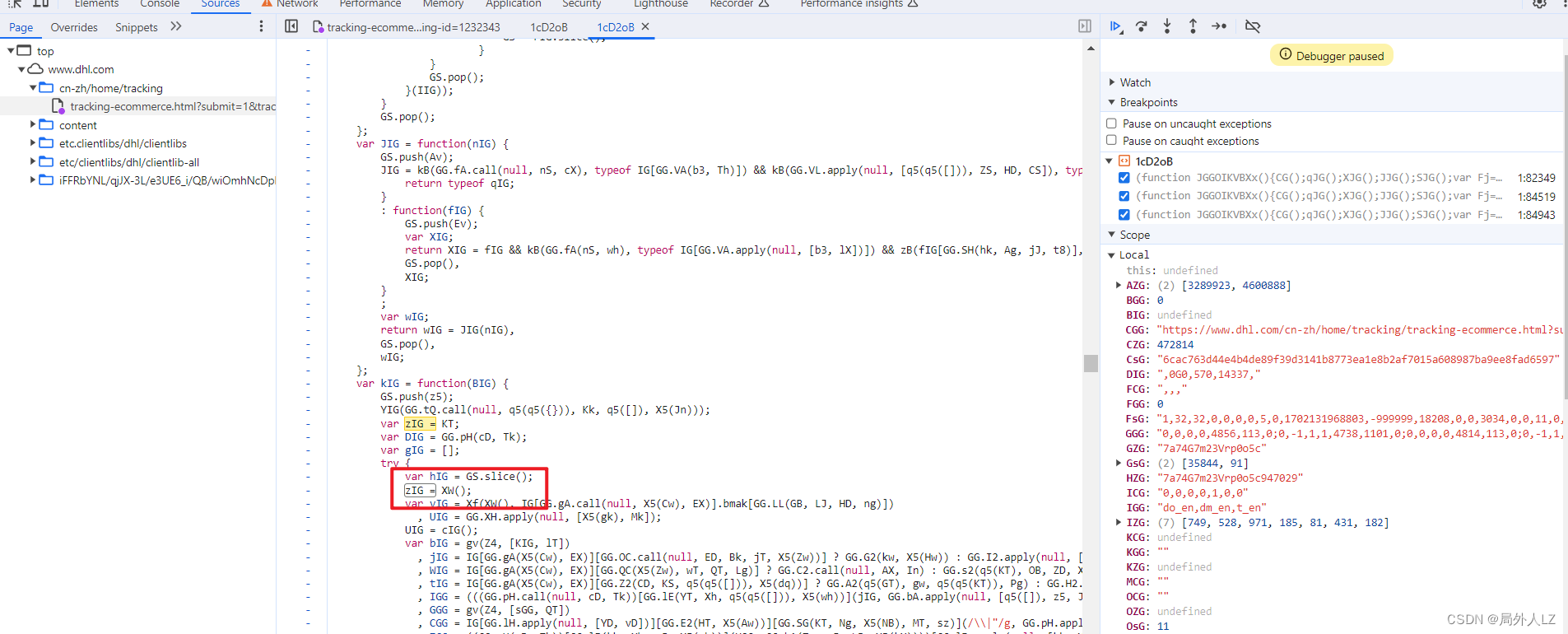
- 分析AZG的值,代码往上找会看到,AZG赋值的地方,切中间的代码并未发现AZG有更改,在AZG打上断点,刷新页面,会发现AZG调用的是EZG方法,鼠标悬浮到EZG,找到EZG方法,分析里面的代码,并把代码扣到dhl.js,并在EZG函数内部打断点
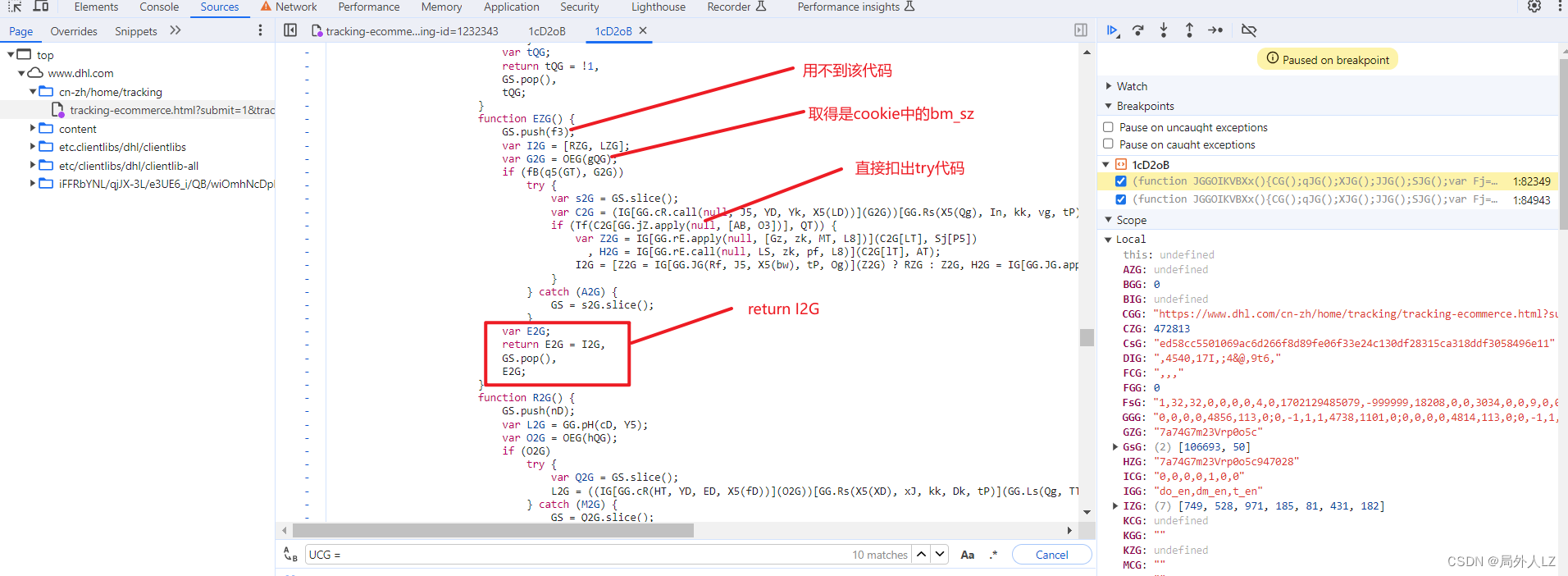
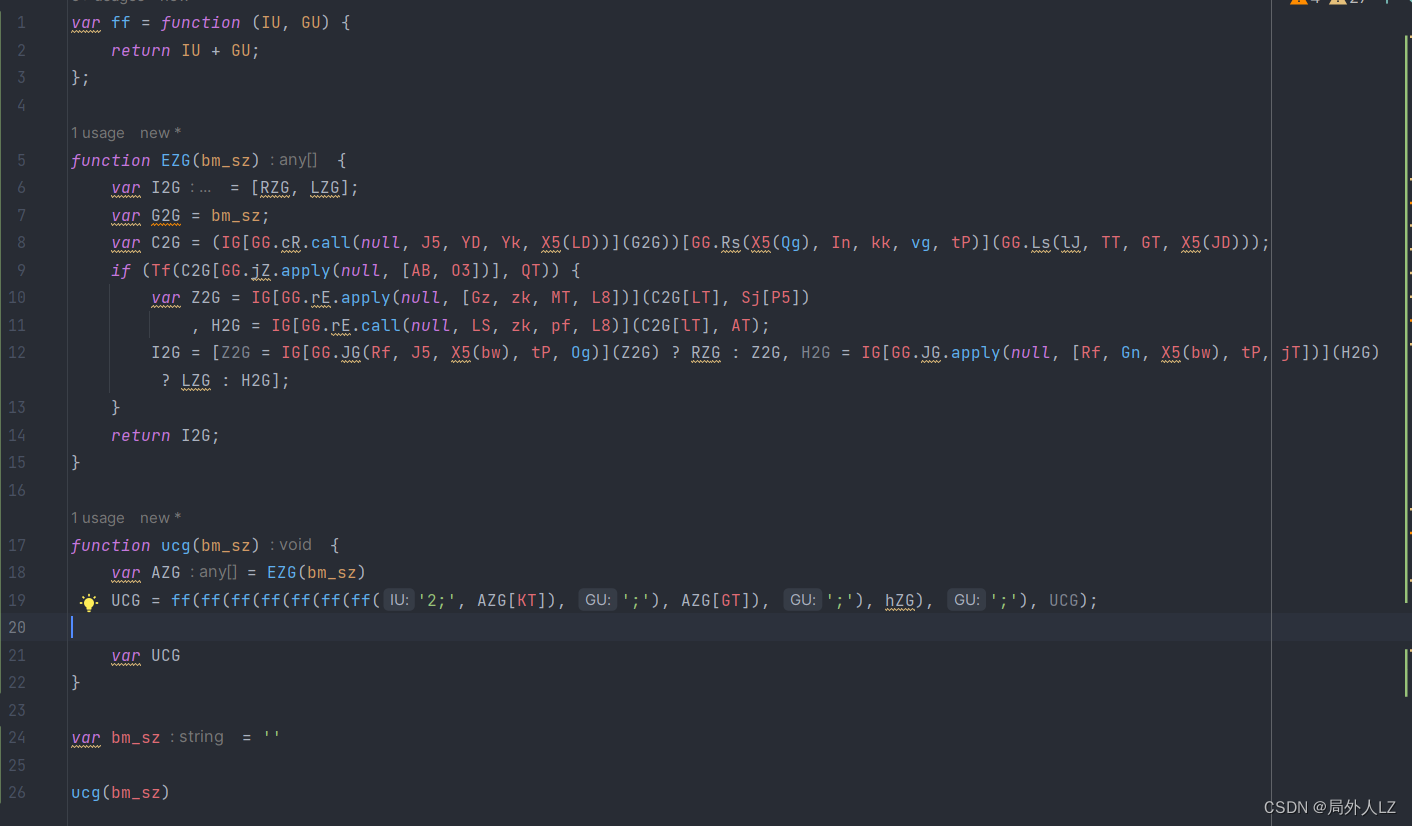
- 点击跳过断点,进入EZG方法内部,分析EZG中try中的代码,把分析后得代码复制到zhl.js
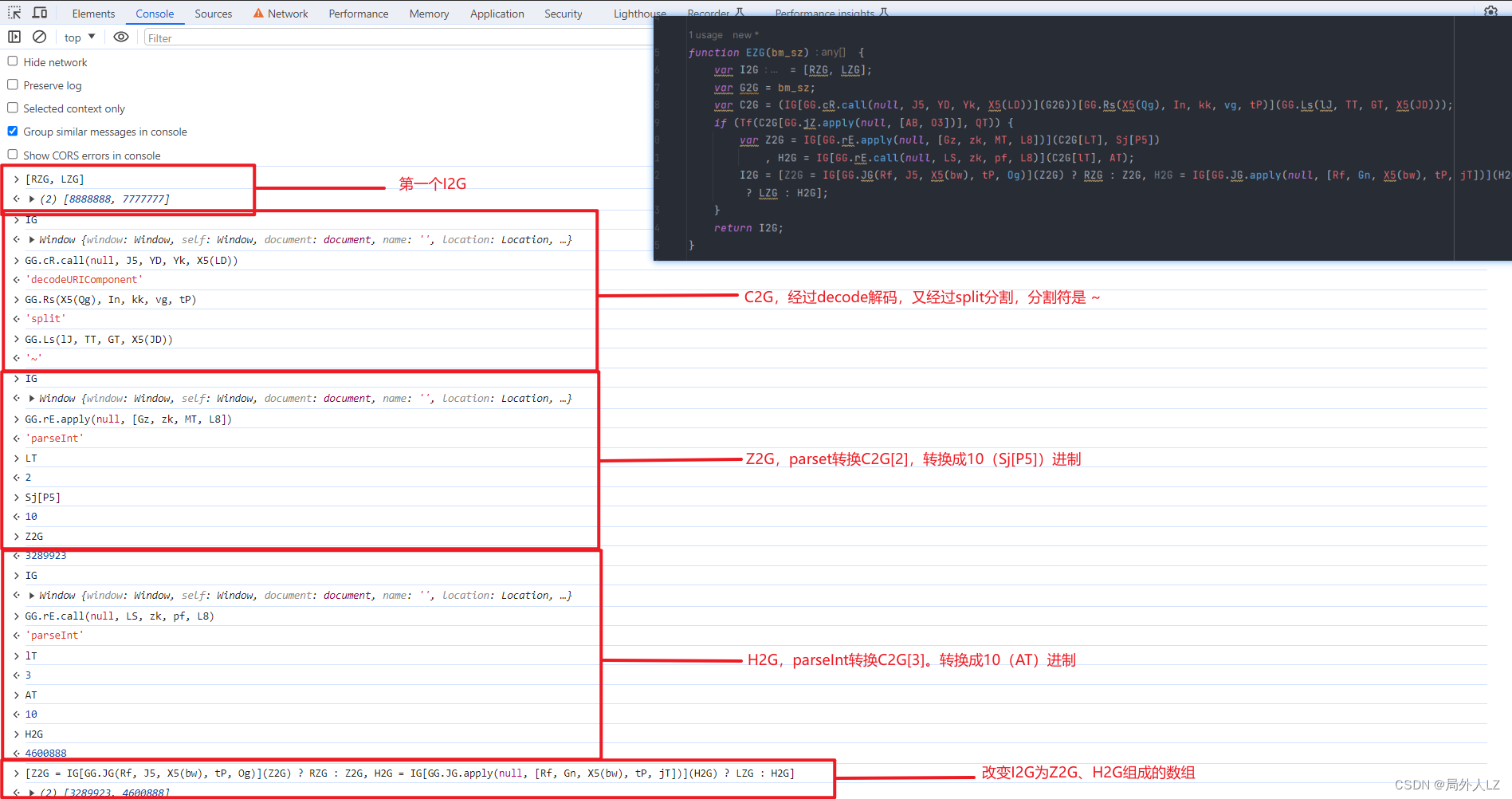

- 再分析AZG[KT]、AZG[GT]分别区的是AZG数组中的哪个值,点击跳过断点,打印出KT、GT,并找到cookie中bm_sz的值复制到dhl.js
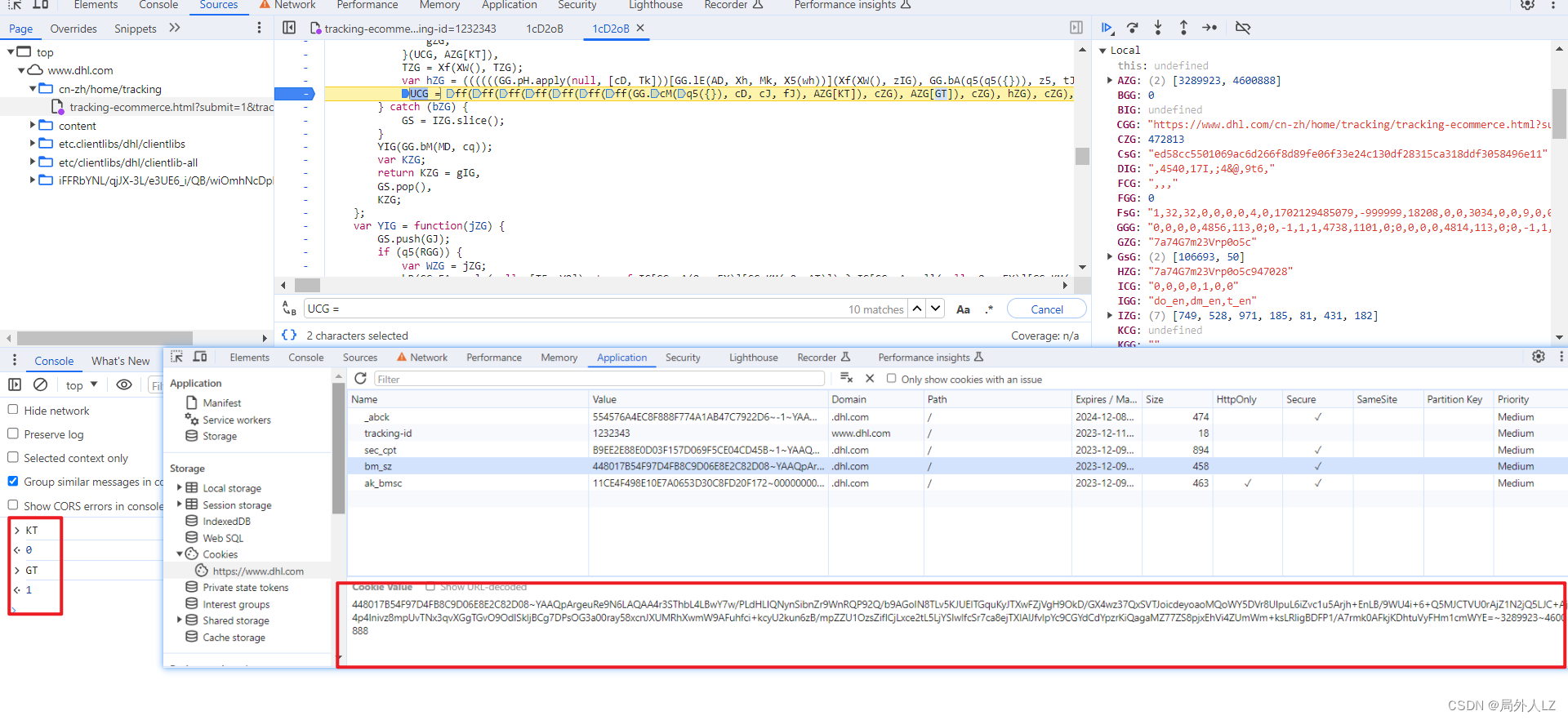
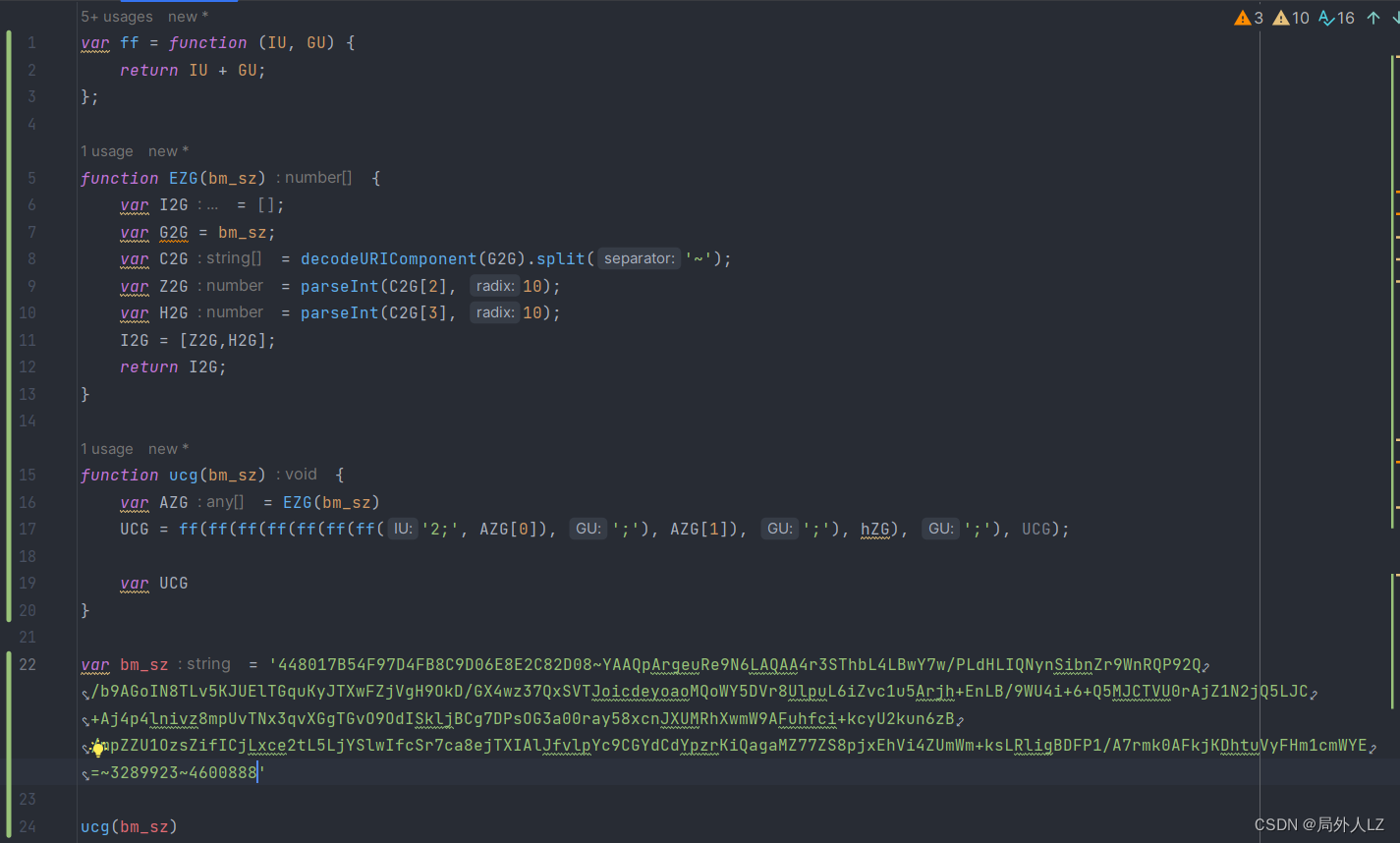
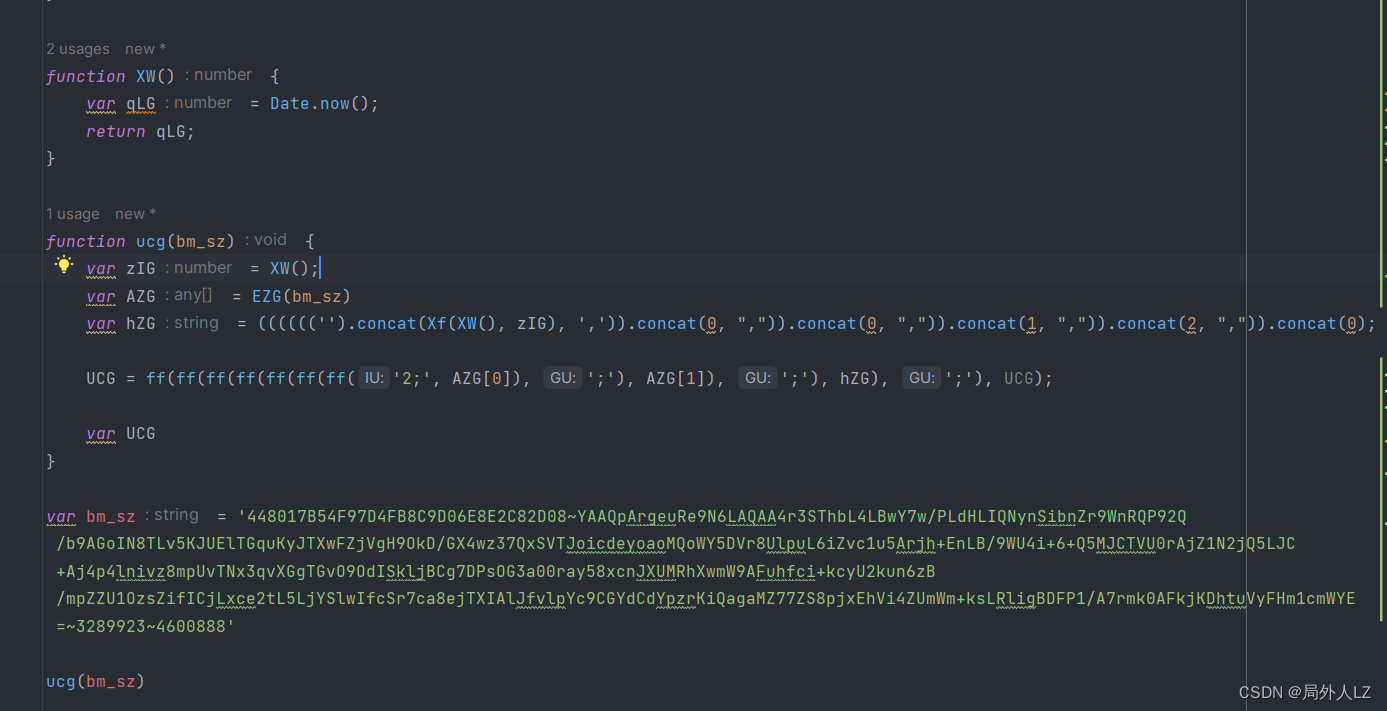
- 分析hZG,hZG就在UCG的上方,在hZG上断点,刷新页面,找到hZG的断点,把相关的参数输出在控制台,会发现它是经过多次concat拼接成的字符串,在控制台多输出几次Xf(XW(), zIG)会发现值是可变的,按照刚才的分析修改zhl.js
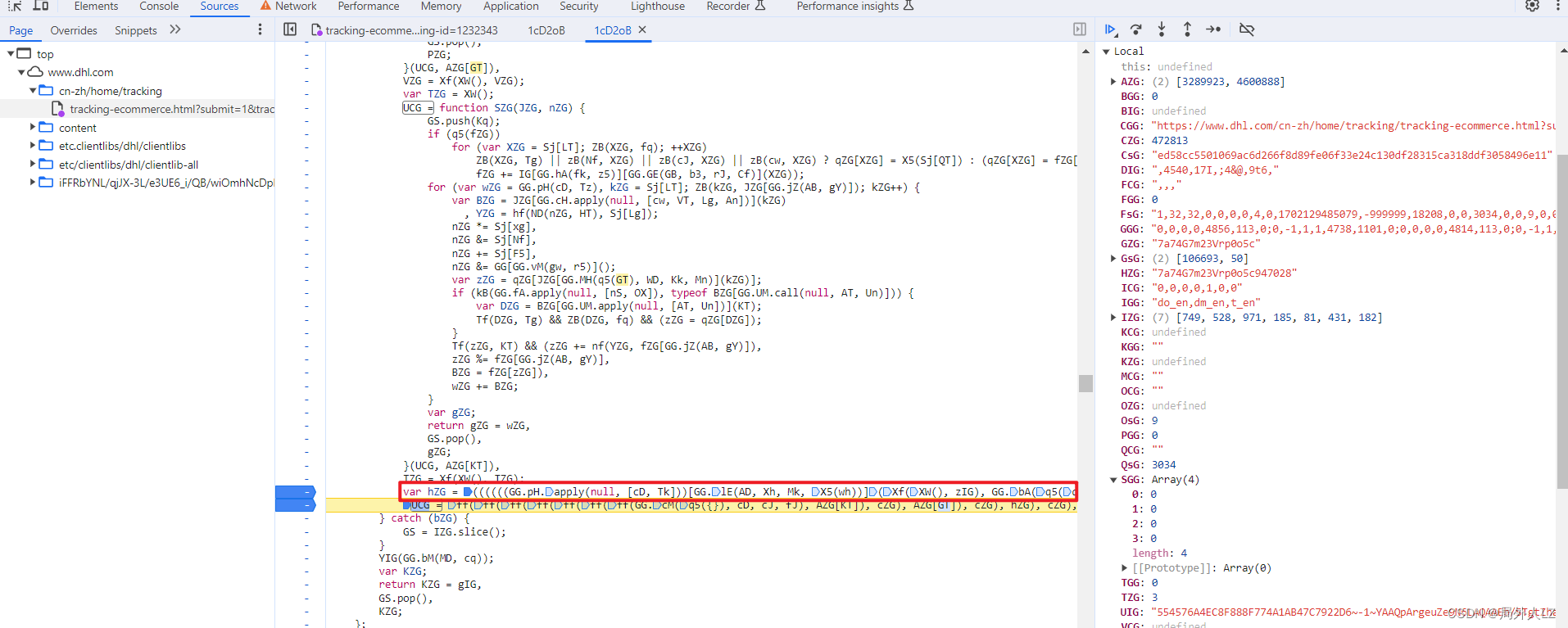
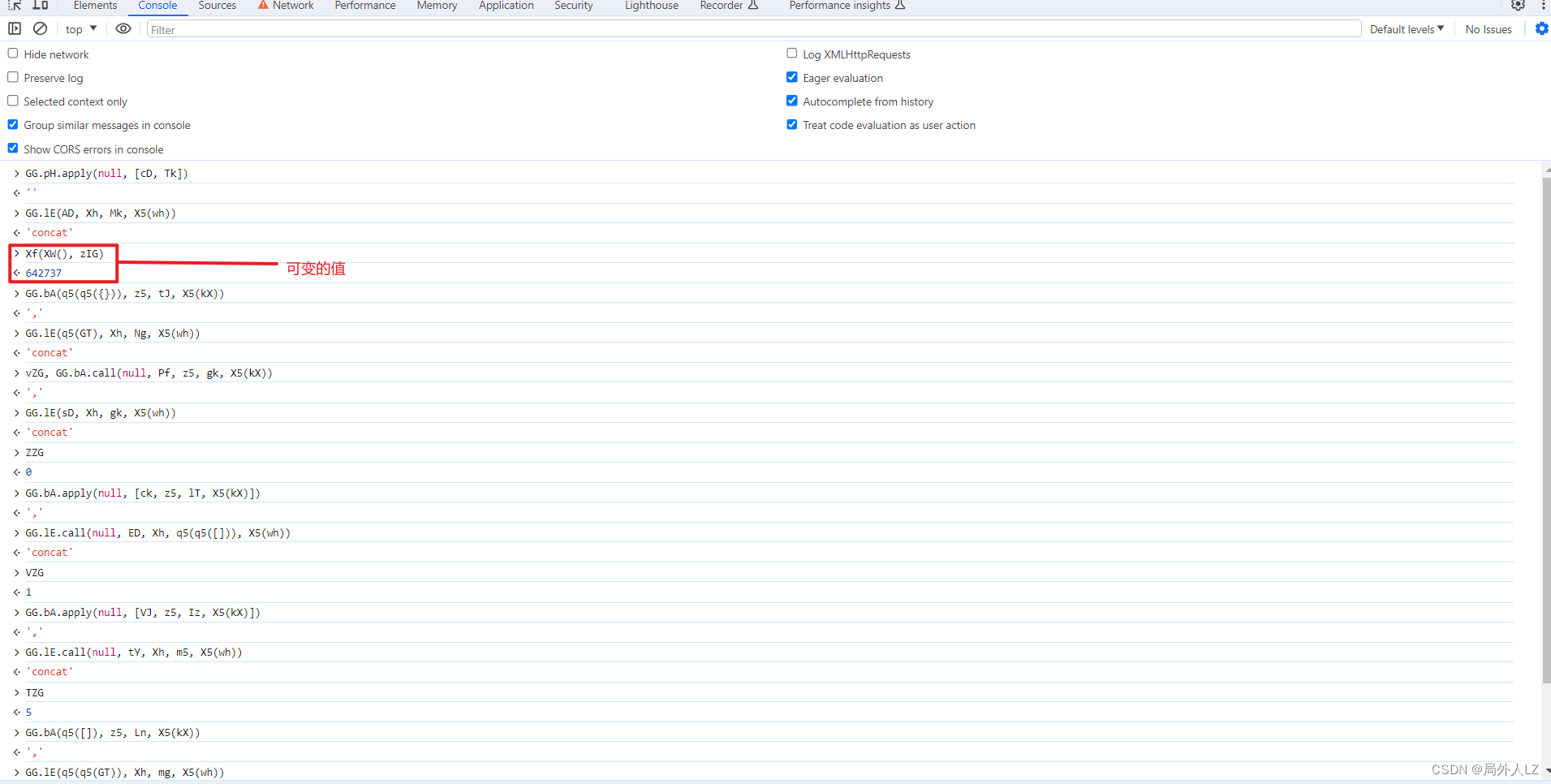
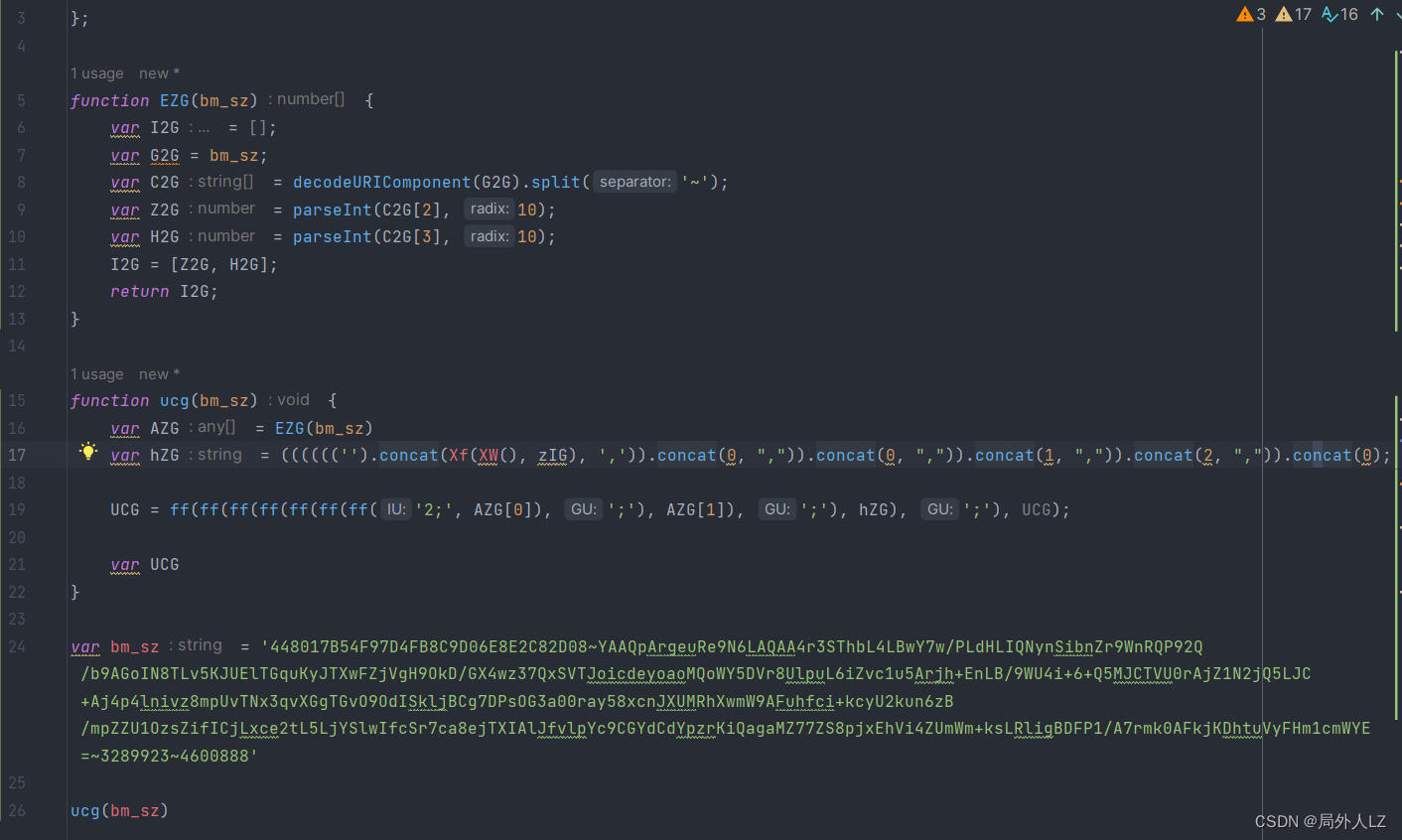
- 分析Xf(XW(), zIG),鼠标悬浮到Xf会找到该方法,代码内部没什么可分析的,把该方法复制到dhl.js即可;鼠标悬浮到XW会找到该方法,在方法内部打上断点,点击跳过断点分析代码,代码内部返回了qLG,qLG是个三元表达式,三元表达式取得的true的结果是个date.now()方法,在dhl.js补上XW方法;搜索zIG,会发现zIG也是XW方法调用,不过这个XW是在代码最上面调用的,在dhl.js补上zIG
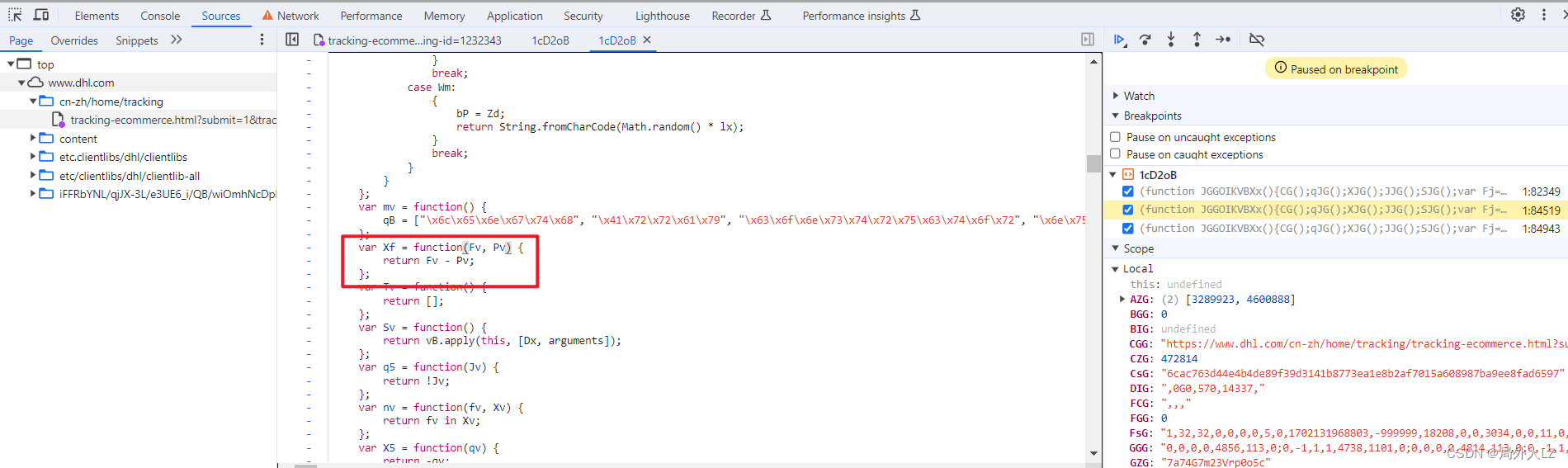
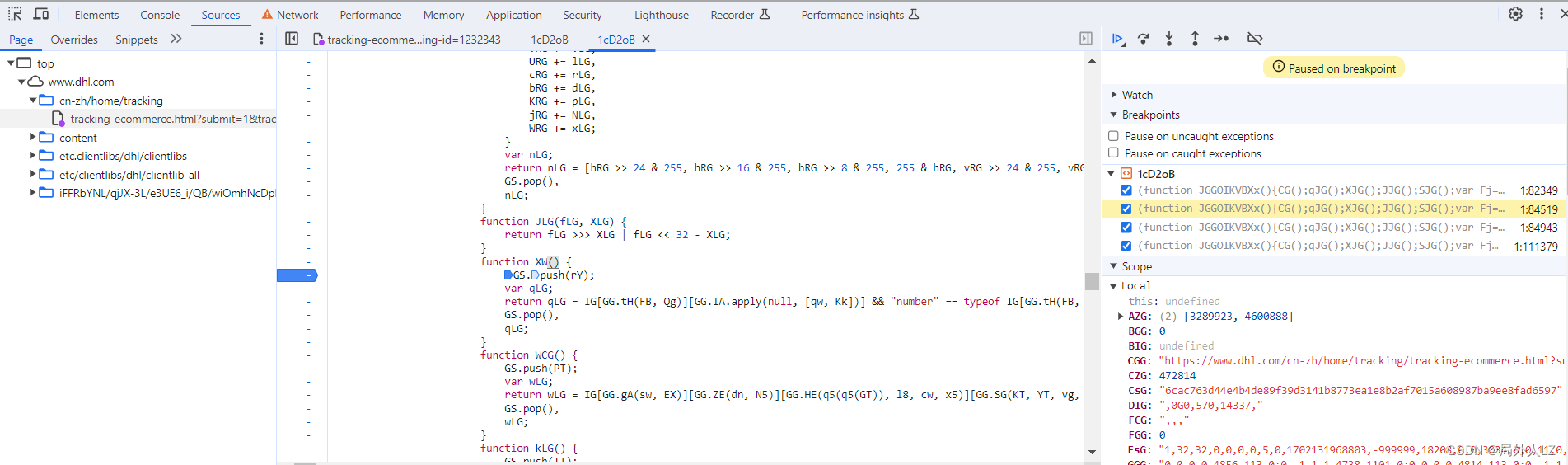
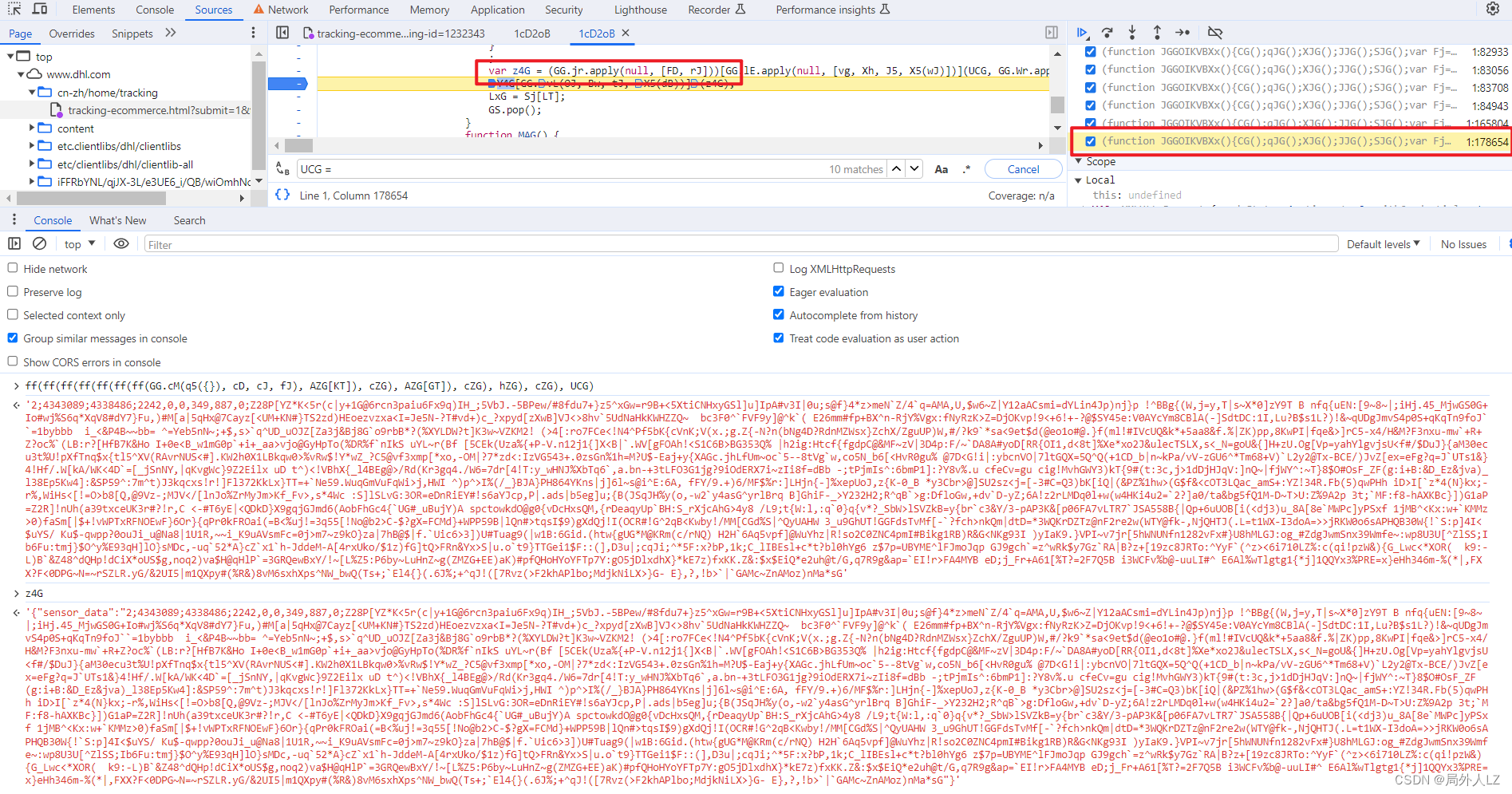
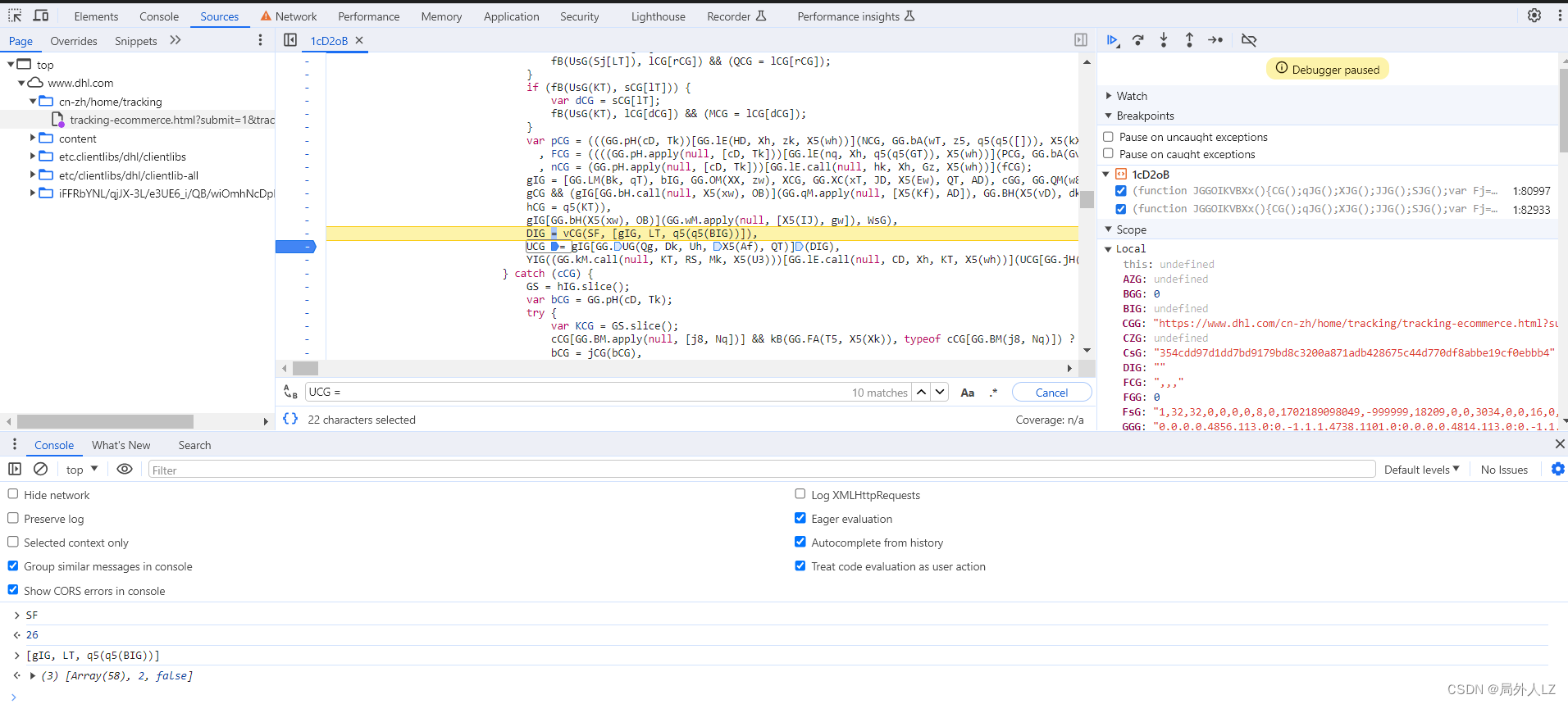
- 清除所有断点,分析参数中的UCG,在代码上方会找到很多UCG赋值的地方,把这些全部复制到dhl.js,其中if中的UCG不用复制,因为打断点会发现不会进入该判断,分析第一个UCG赋值的地方还有个UCG,所以在该UCG打断点1:82933,搜索UCG=在除了刚才那几个UCG其它的打断点,刷新页面找到上一个UCG赋值的地方,找到后把这个UCG也复制到dhl.js,并清除其他断点,把这几个UCG扣下来就算结束了
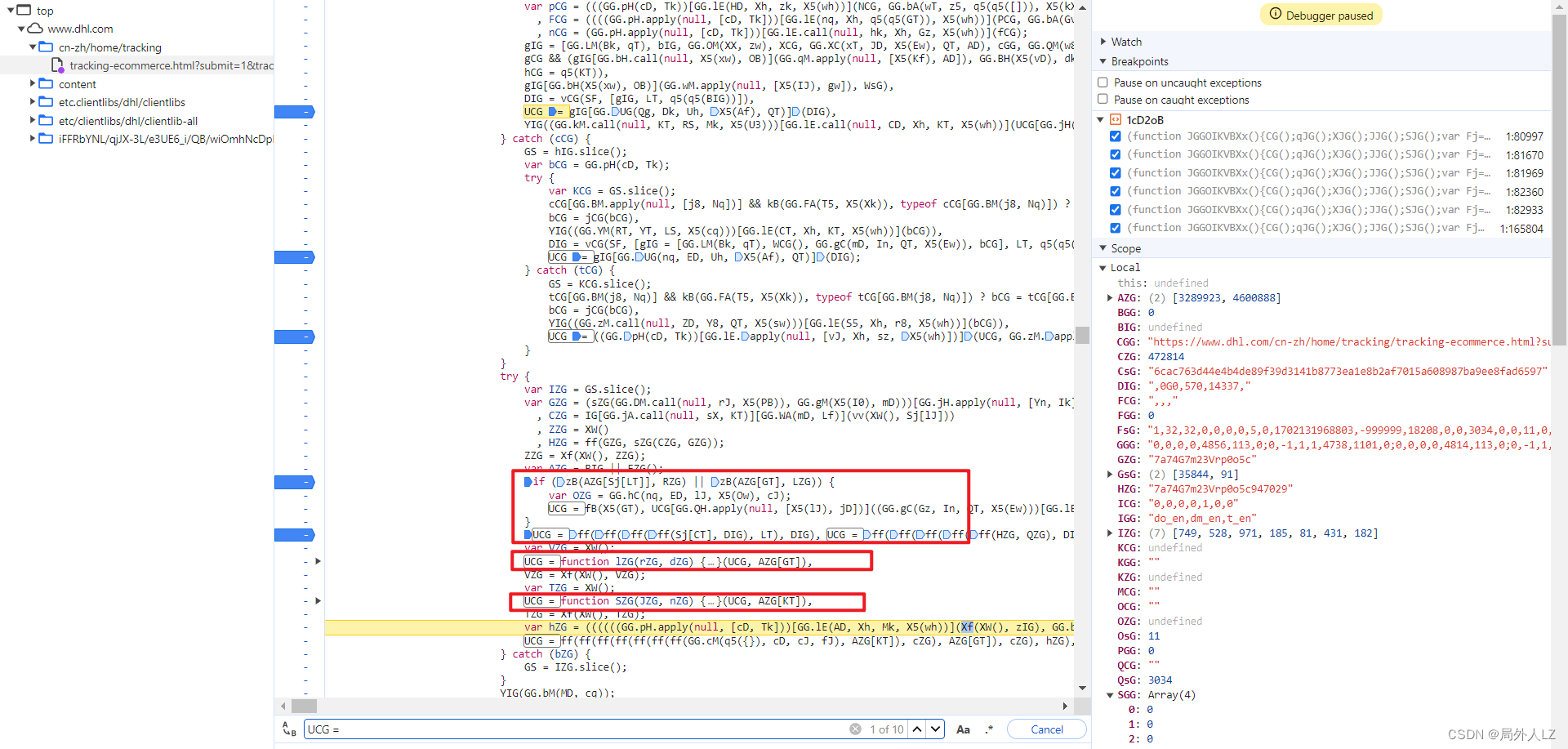
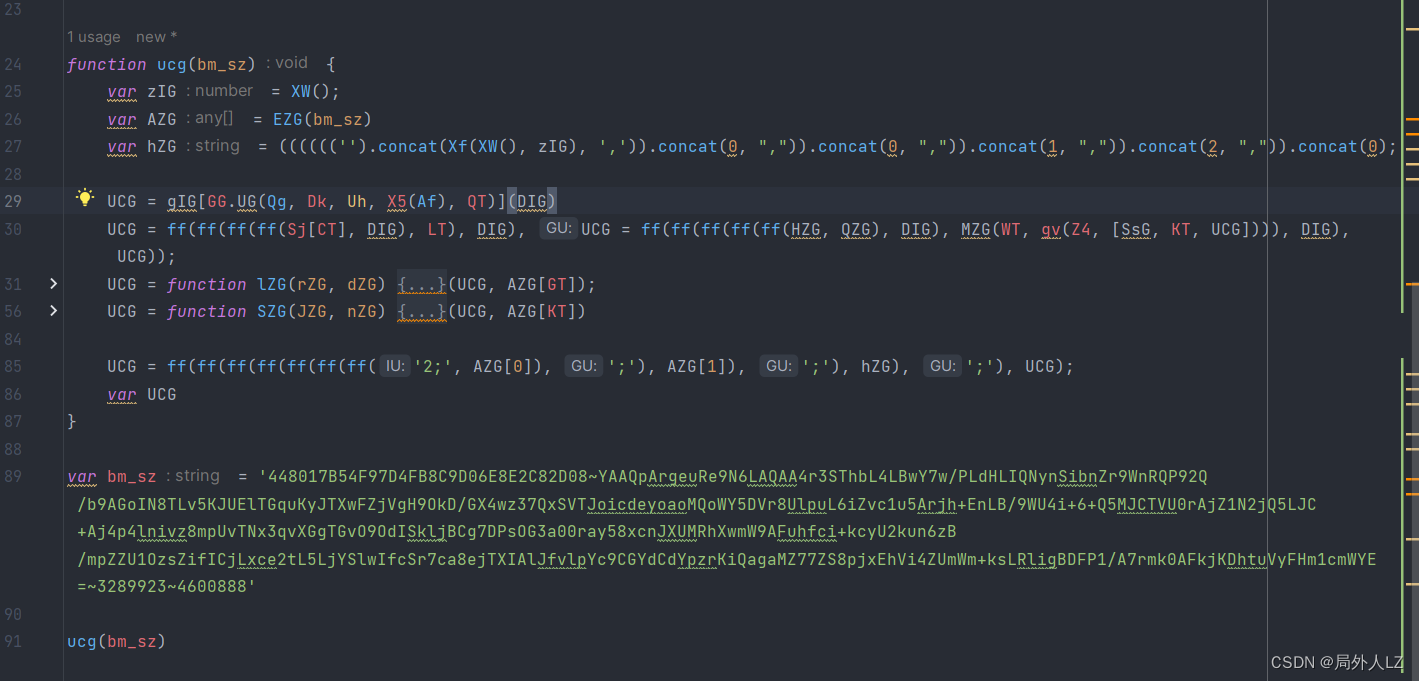
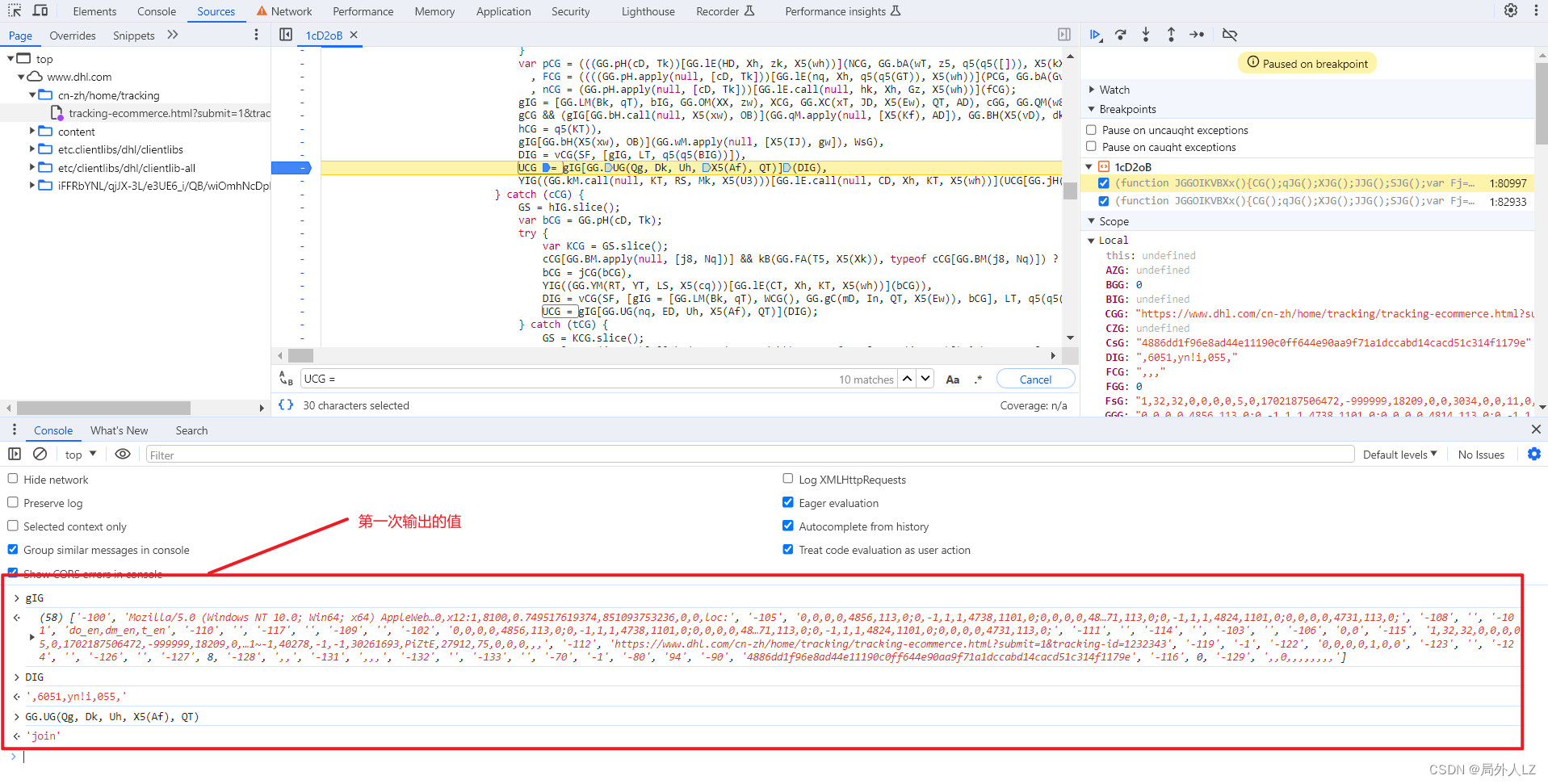
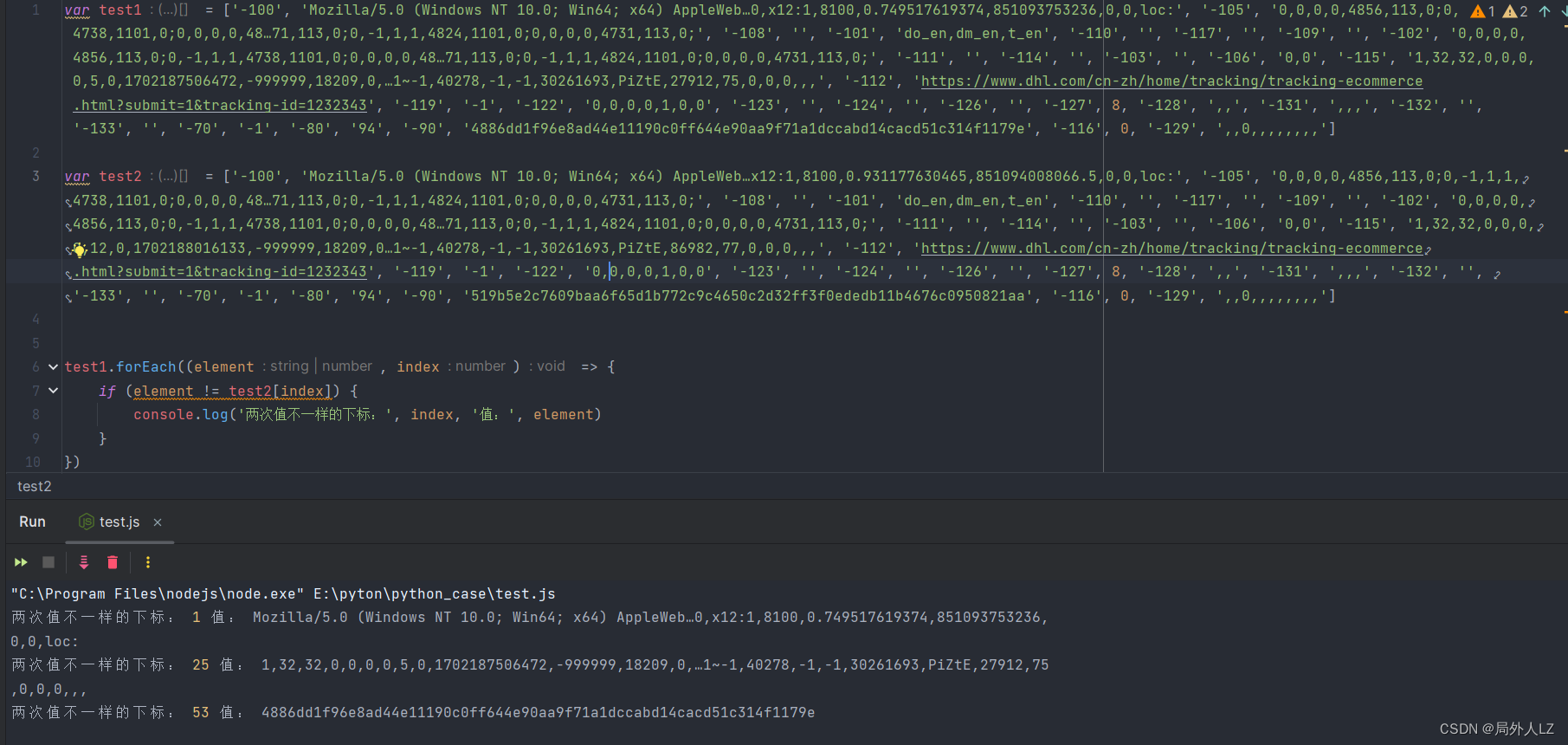
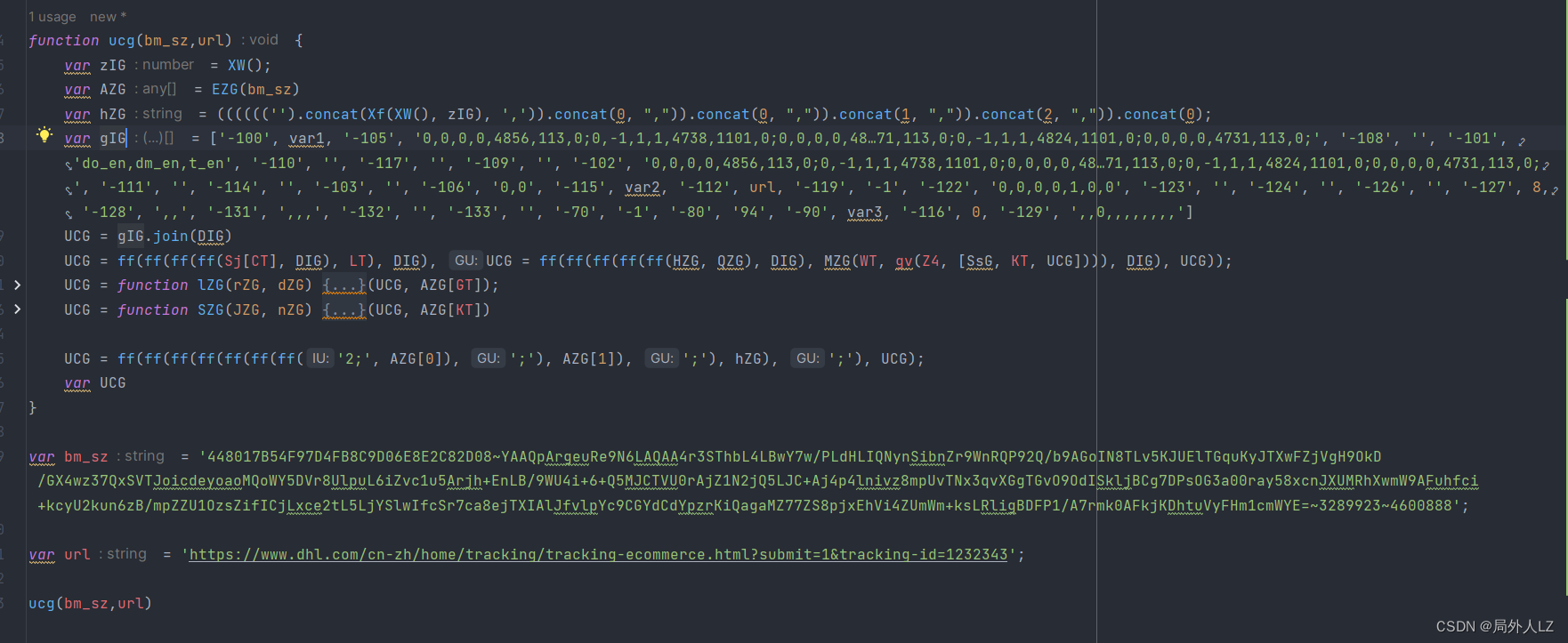
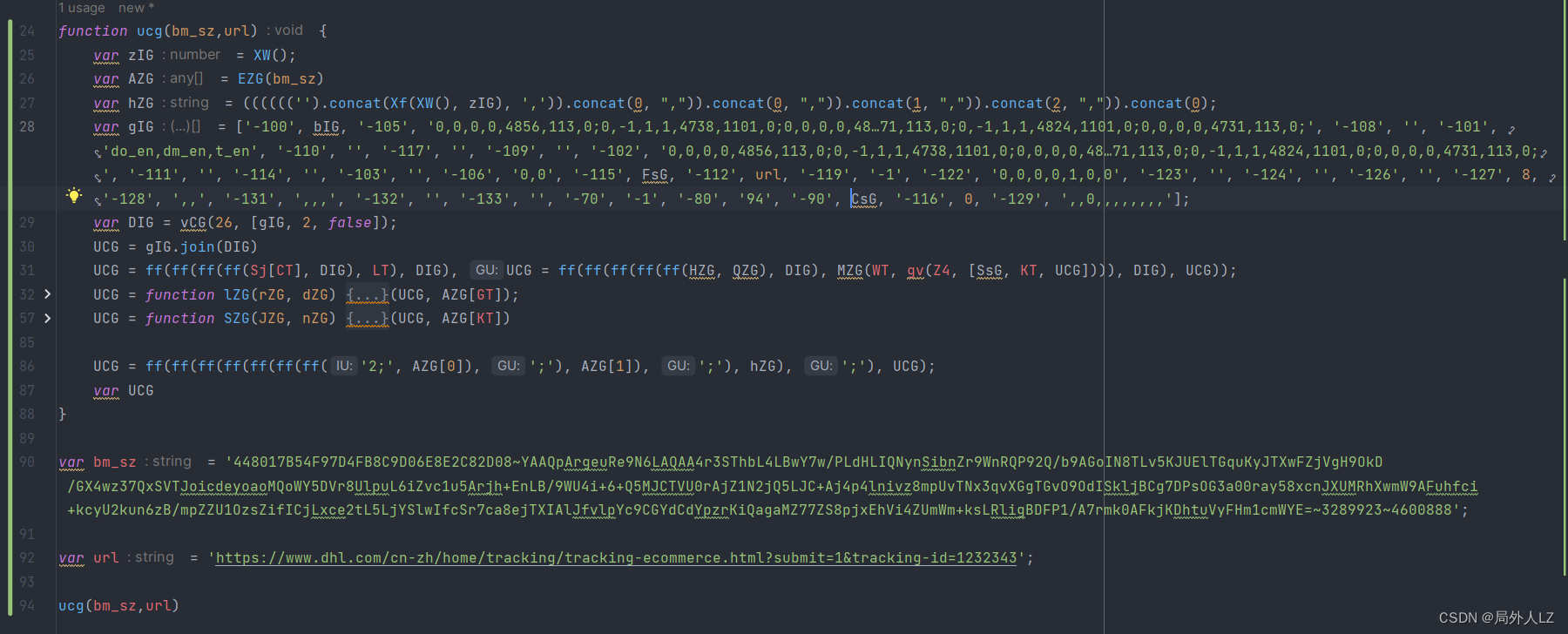
- 先扣第一个UCG = gIGGG.UG(Qg, Dk, Uh, X5(Af), QT),刷新页面会进入该UCG断点,输出相关的值,再刷新页面进入该断点,输出相关的值,对比两次结果会发现GG.UG(Qg, Dk, Uh, X5(Af), QT)是join方法,用来拼接数组;DIG之个可变的值;至于gIG是个数组,至于数组里面哪些是固定的值,可以写个js做对比,对比后会发现只有1、25、53是可变的,还有一条要注意的是有个url这个要通过参数传过去;根据分析补充UCG代码
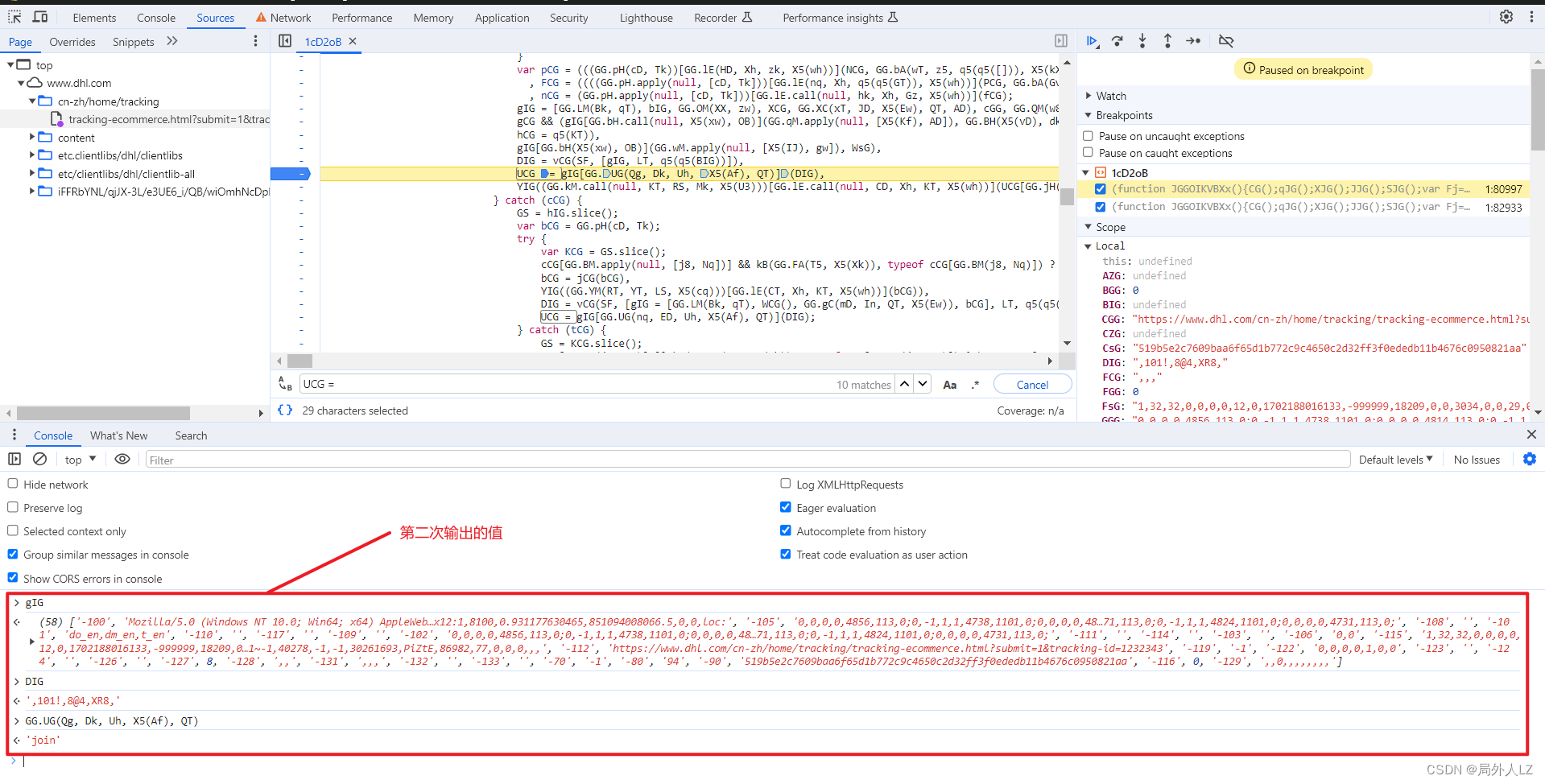
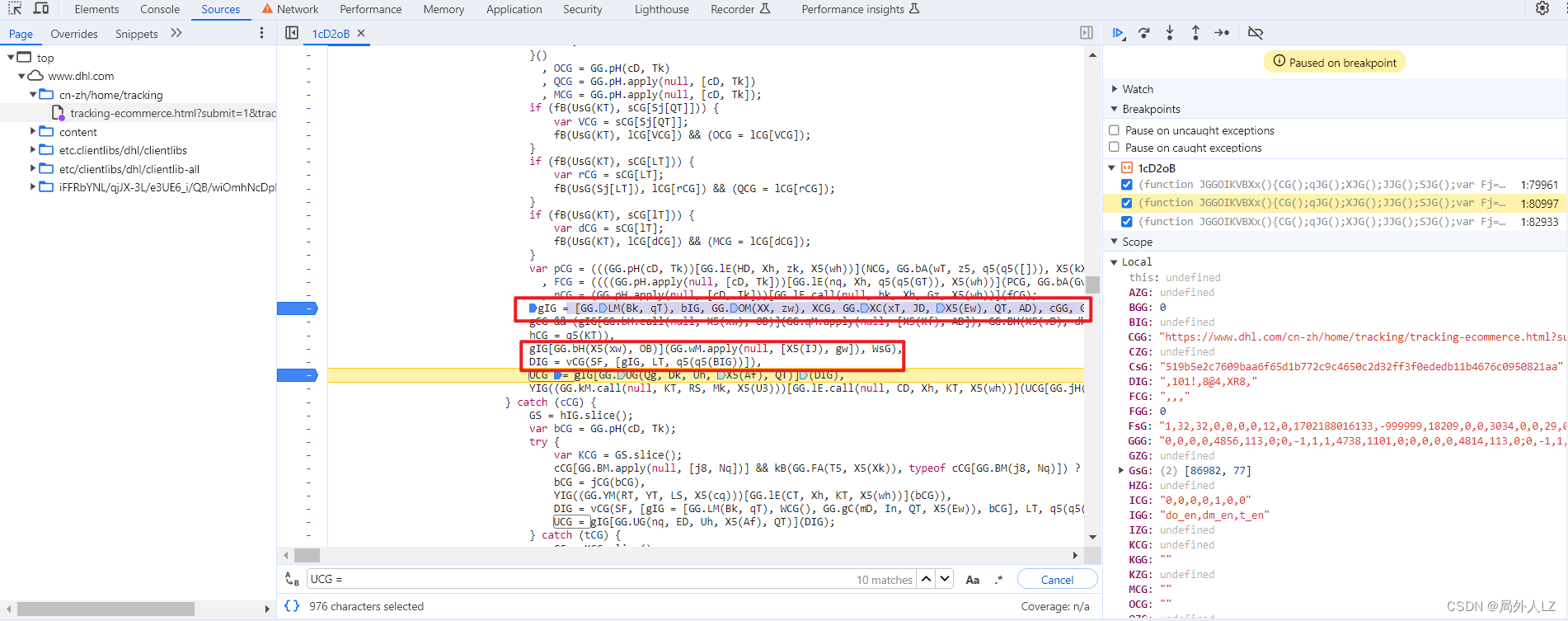
- 找出gIG、DIG动态值生成,代码往上找会看到gIG、DIG生成的地方,在gIG生成的地方打个断点,刷新页面,分析gIG赋值的地方知道1、25、53分别对应bIG、FsG、CsG;DIG是一个vCG函数,参数分别是26、[gIG,2,false];根据分析补充代码
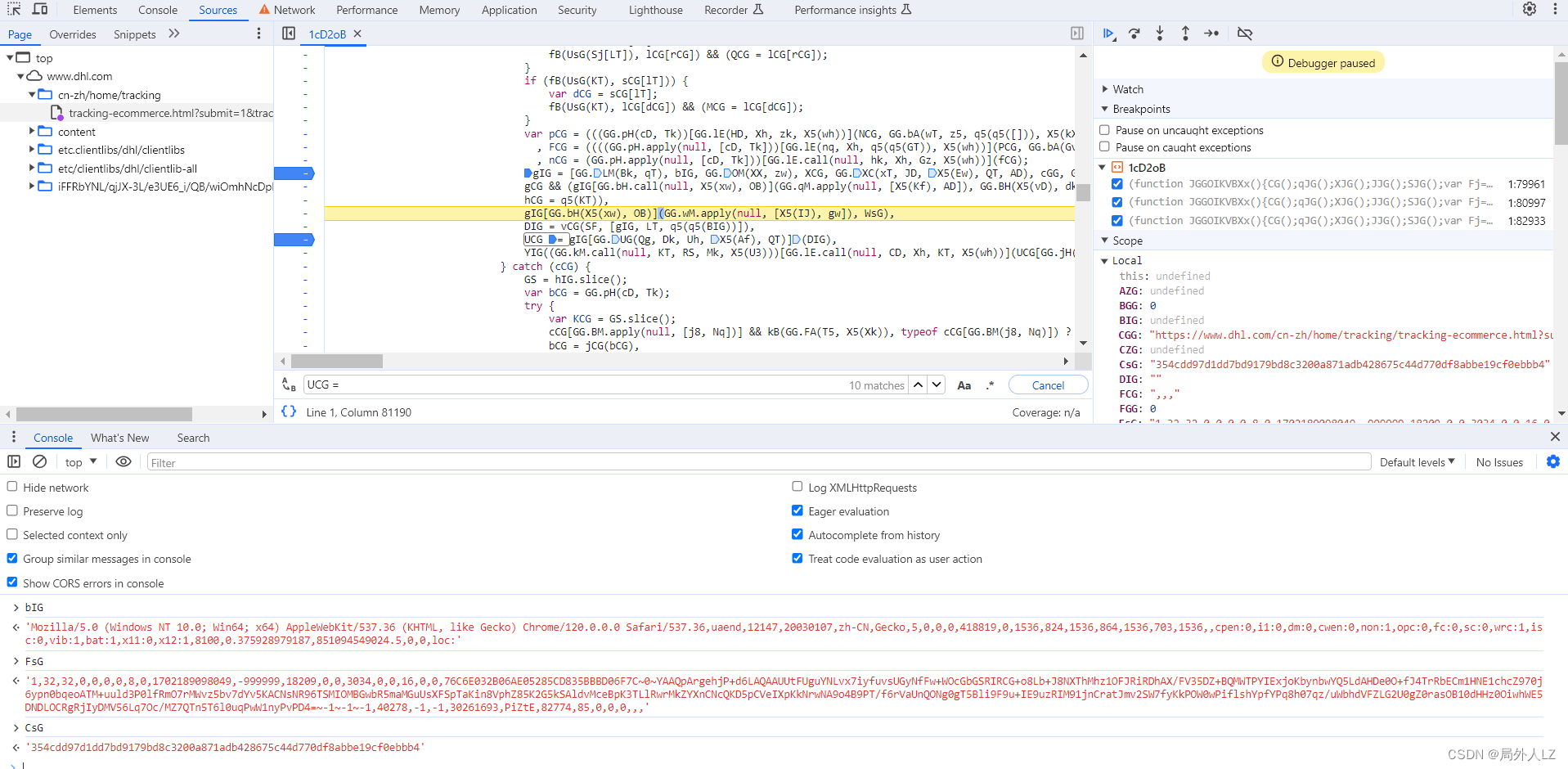
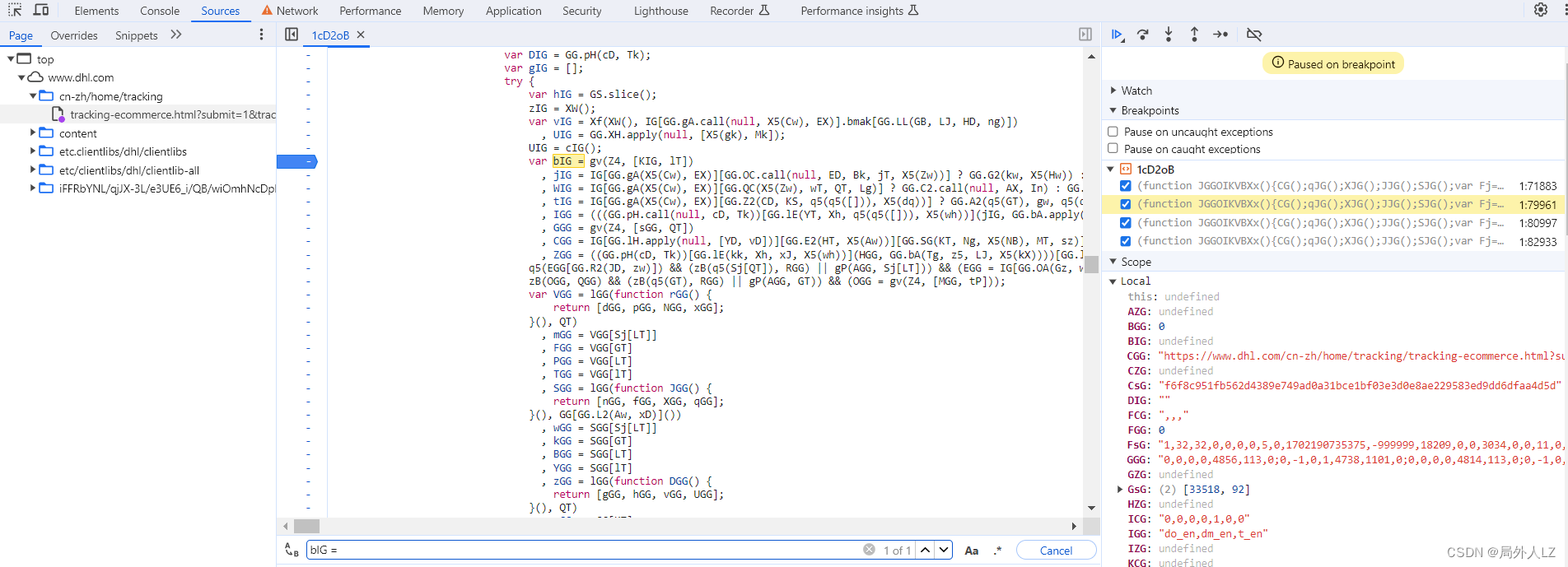
- 分析bIG、FsG、CsG生成,搜索bIG = 会找到,bIG赋值的地方,在bIG赋值地方打个断点,刷新页面,找到bIG断点,分析代码会发现bIG是经过gv方法生成的,参数分别是30、KIG方法和3组成的数组,鼠标悬浮到gv方法,找到方法,在方法内部每个case断点,点击跳过断点,当执行到第一个case时分析代码,会发现,调用了KIG方法,参数空数组。清除之前gv断点,找到KIG,在KIG方法内部打上断点按照之前扣代码的方法分析代码,补上KIG方法

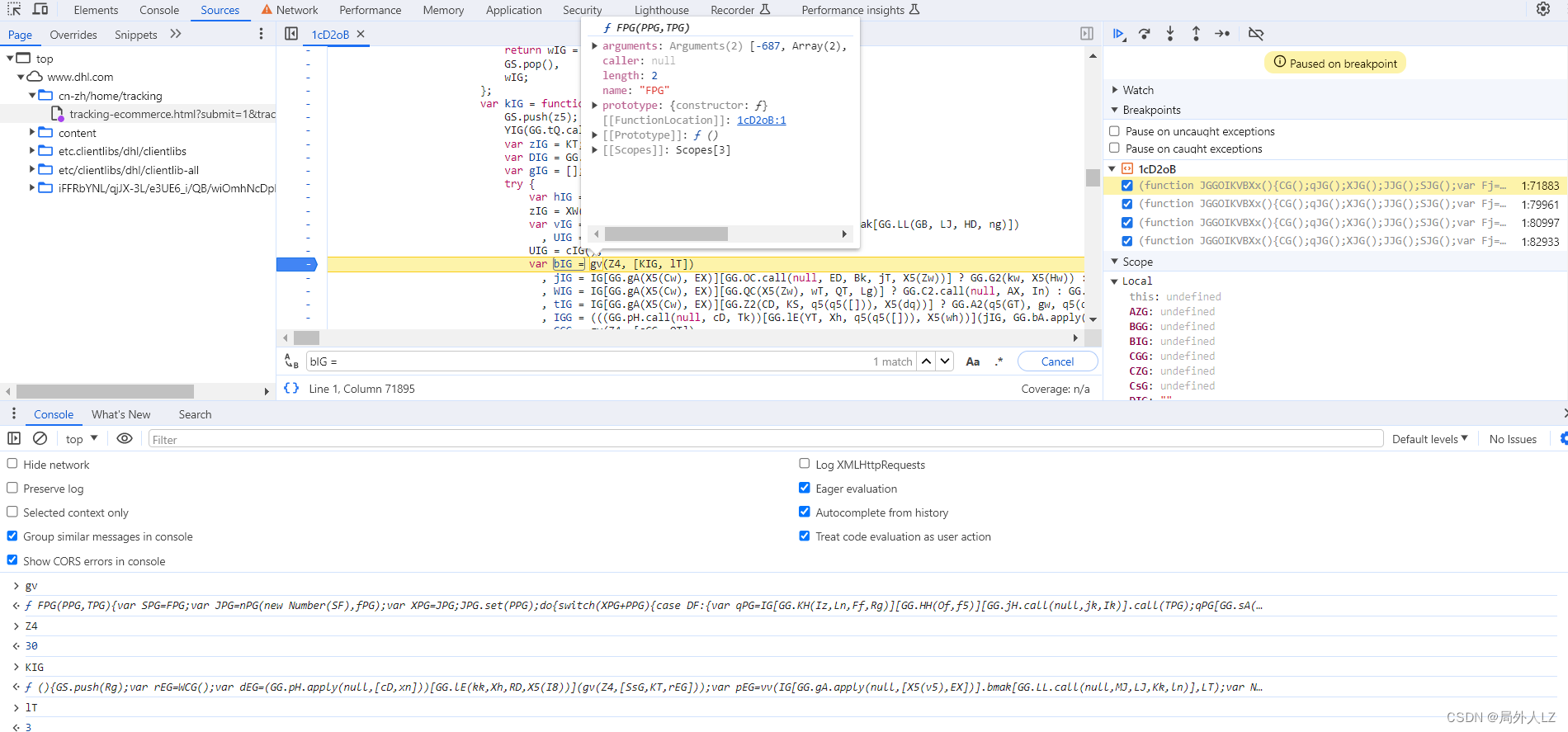


- 按照之前的方法补出其他UCG代码就行
五、总结
akamai改动太频繁,改动完之后,还要重新分析代码,不值当去扣代码,有网站会提供akamai相关的接口,只不过是付费的,可以在网上找找,这次补代码与上次补代码只间隔了一星期,里面有些变量的数值就有小改动;akamai扣代码流程大概就这样,这里不再继续往下扣了,我把上次扣成功的代码贴到这里,供各位参考
- dhl.js
c6T = [300000, 4095, 1, 60, 40, 20, 0, 5, 16, 1000, 4, 21, 22, 30, 31, 8888888, 7777777, 8, 126, 47, 2, 10, 0.8, 0.7, 0.98, 0.4, 0.9, 0.95, 0.1, 0.025, 0.08, 0.075, 0.22, 255, 6, 4294967296, 999999, 13, 11, 24, 32, 3600000, 65535, 65793, 4294967295, 8388607, 4282663, 39, 3, 4064256, 9]function B5T() {return VVT = Date.now && Date.now(), VVT;
}var r1T = function () {var C4T = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36";var P4T = "8108";var Q4T = 850845805802.5;var f4T = -1;var hzT = -1;var TzT = -1;var dzT = -1;var JzT = -1;var KzT = -1;var XzT = -1;var HzT = -1;HzT = 0;f4T = 1920;hzT = 1040;TzT = 1920;dzT = 1080;JzT = 150;KzT = 1920;XzT = 1920;NzT = 41869,FXT = 0;var wzT = Math.random();var LzT = parseInt(1000 * wzT / 2, 10);var nzT = ('').concat(wzT);nzT = Mn(nzT.slice(0, 11), LzT);var tzT = ["20030107","zh-CN","Gecko",5];var DzT = tzT[0];var EzT = tzT[1];var szT = tzT[2];var czT = tzT[3];var jzT = 0;var FzT = 0;var IzT = 0;var lzT;return lzT = (((((((((((((((((((((((('').concat(C4T, ',uaend,')).concat(function gzT() {var mzT;var BzT;var kzT = 1;var CzT = 1;var PzT = 0;var QzT = 0;var fzT = 1;var h3T = 1;var T3T = 1;var d3T = 0;var J3T = 1;var K3T = 1;var X3T = 0;var H3T = 1;mzT = 1;BzT = 1;var V3T;return V3T = Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(Mn(kzT, BXT(CzT, 1)), BXT(PzT, 2)), BXT(QzT, c6T[48])), BXT(fzT, 4)), BXT(h3T, 5)), BXT(T3T, c6T[34])), BXT(d3T, 7)), BXT(mzT, 8)), BXT(BzT, 9)), BXT(J3T, 10)), BXT(K3T, 11)), BXT(X3T, 12)), BXT(H3T, 13)),V3T;}(), ',')).concat(DzT, ',')).concat(EzT, ',')).concat(szT, ',')).concat(czT, ',')).concat(jzT, ',')).concat(FzT, ',')).concat(IzT, ',')).concat(NzT, ',')).concat(0, ',')).concat(f4T, ',')).concat(hzT, ',')).concat(TzT, ',')).concat(dzT, ',')).concat(KzT, ',')).concat(JzT, ',')).concat(XzT, ',')).concat(function x3T() {var W3T = [",cpen:0","i1:0","dm:0","cwen:0","non:1","opc:0","fc:0","sc:0","wrc:1","isc:0","vib:1","bat:1","x11:0","x12:1"];var M3T;return M3T = W3T.join(','),M3T;}(), ',')).concat(P4T, ',')).concat(nzT, ',')).concat(Q4T, ',')).concat(0, ',')).concat(HzT, '#H,\x01 '),lzT;
};function cST(bm_sz) {var YWT = bm_sz;var EWT = decodeURIComponent(YWT).split("~");var sWT = parseInt(EWT[2], 10), cWT = parseInt(EWT[3], 10);tWT = [sWT, cWT];return FWT = tWT}function ZST(Pz, xz) {var Lz = xz[0];var Vz = xz[1];var Rz = xz[2];(function sz() {fz = [];var Cj = 53;var Zj = "case gC:";var pj = 1663;var Dj = 0;for (var Fj = Cj; Fj < pj; ++Fj) {var Xj = "function lz(Pz,xz){'use strict';var Bz=lz;switch(Pz){case sC:{var Lz=xz[sr];var Vz=xz[gr];var Rz=xz[Nr];A6.push(Sz);(function sz(){A6.push(gz);if(Nz(typeof fz[h6],b6(h7.Lw(S6([]),Uz,xC,vj),[][[]]))){A6.pop();return;}function hj(wj){A6.push(Ij);var bj;return bj=Jj(typeof wj,h7.pw(Gj,BC))?h7.Nw(Tj,qj):b6(b6(h7.sw.apply(null,[LC,Aj]),wj),h7.gw(Hj,VC)),A6.pop(),bj;}var kj=h7[h7.Yw.call(null,Ej,rj,tj)].call(Bz);var Cj=kj[h7.fw(RC,Qj)](hj(mj[h6]),dj[h6]);var Zj=hj(Yj[h6]);var pj=kj[h7.fw(RC,Qj)](Zj,b6(Cj,cj[h6]));var Dj=h6;for(var Fj=Cj;Fj<pj;++Fj){var Xj=kj[h7.Uw.call(null,Mj,zj)](Fj);if(Xj!=jj&&Xj!=qj&&Xj!=nj){Dj=(Dj<<Oj)-Dj+Xj;Dj=Dj|h6;}}fz[h6]=Dj?Dj:H6;h7[h7.Sw.call(null,Kj,SC)][h6]=b6(h6,H6);A6.pop();}());if(h7.q7[sr]>sr){Wj(fz[sr]-lj[sr]);}var Pj;var xj;var Bj=S6(h6);var Lj=h7.Hb(Vj,Rj);var Sj=Rz?gj:sj;if(S6(Nj)&&(Nj=h7.Tb.apply(null,[fj,Uj,vn]),UM(Vz,h6)&&hn(Vz,wn)))for(Pj=h6;hn(Pj,wn);++Pj)if(Nz(Pj,Vz))for(xj=h6;M6(xj,In);++xj)Nj+=Pj[h7.Fw(bn,Jn)]();for(;;){for(Lj=h7.Hb.apply(null,[Vj,Rj]),Bj=S6(h6),Pj=h6;M6(Pj,b6(v7[h7.qb(Cc,gj)][h7.kb.call(null,Gn,An)](Hn(v7[h7.qb.apply(null,[Cc,gj])][h7.Eb(Aj,qj,Qc,zj)](),Sj)),Sj));++Pj){for(xj=h6;M6(xj,b6(v7[h7.qb.apply(null,[Cc,gj])][h7.kb(Gn,An)](Hn(v7[h7.qb.apply(null,[Cc,gj])][h7.Eb.apply(null,[S6(S6(h6)),Tn,Qc,zj])](),Sj)),Sj));++xj)Lj+=Nj[v7[h7.qb.call(null,Cc,gj)][h7.kb(Gn,An)](Hn(v7[h7.qb(Cc,gj)][h7.Eb.apply(null,[qn,S6(H6),Qc,zj])](),Nj[h7.Cw.apply(null,[mc,kn])]))];Lj+=h7.Hb.call(null,Vj,Rj);}for(Pj=h6;M6(Pj,Lz[h7.Cw.apply(null,[mc,kn])]);++Pj)if(Nz(En(H6),(Lz[Pj][h7.Fw.apply(null,[bn,Jn])]())[h7.fw(dc,Qj)](Lj))){Bj=S6(H6);break;}if(Bj){var rn;return rn=Lj,A6.pop(),rn;}}A6.pop();}break;case gC:{if(sr){throw Math.random();}}break;}}".charCodeAt(Fj);if (Xj != 10 && Xj != 13 && Xj != 32) {Dj = (Dj << 5) - Dj + Xj;Dj = Dj | 0;}}fz[0] = Dj ? Dj : 1;}());var Pj;var xj;var Bj = true;var Lj = ",";var Sj = 3;Nj = ""if (!Nj && (Nj = "abcdefghijklmnopaqrstuvxyzABCDEFGHIJKLMNOPAQRSTUVXYZ!@#%&-_=;:<>,~", (Vz >= 0) && Vz <= 9)) for (Pj = 0; Pj <= 9; ++Pj) if (Pj !== Vz) for (xj = 0; xj < 20; ++xj) Nj += Pj.toString();for (; ;) {for (Lj = ",", Bj = true, Pj = 0; Pj < Math.floor(Math.random() * Sj) + Sj; ++Pj) {for (xj = 0; xj < Math.floor(Math.random() * Sj) + Sj; ++xj) Lj += Nj[Math.floor(Math.random() * Nj.length)];Lj += ",";}for (Pj = 0; Pj < Lz.length; ++Pj) if (-1 !== (Lz[Pj].toString()).indexOf(Lj)) {Bj = false;break;}if (Bj) {return Lj}}
}function HY(sHA) {for (var CHA = 0, bHA = 0; bHA < sHA.length; bHA++) {var tHA = sHA.charCodeAt(bHA);tHA < 128 && (CHA += tHA);}return CHA
}var ZY = function (Oc, pc) {return Oc & pc;
};
var zY = function (gET, mET) {return gET % mET;
};
var r6T = function (O6T, p6T) {return O6T >> p6T;
};var zn = function (Vn, An) {return Vn < An;
};
var Jt = function (jET, FET) {return jET === FET;
};
var Mn = function (bn, Gn) {return bn + Gn;
};var BXT = function (rET, OET) {return rET << OET;
};var U1T = function (bm_sz, _abck, html_url) {A1T = B5T()var sST = cST(bm_sz);RST = 0R1T = r1T()vST = "0,0,0,0,4873,113,0;0,-1,0,1,4763,1101,0;0,0,0,0,4880,113,0;0,-1,0,1,4870,1101,0;0,-1,0,1,4664,1101,0;0,0,0,0,4888,113,0;0,-1,0,1,4754,1101,0;0,0,0,0,4686,113,0;0,-1,0,1,3602,1101,0;"L1T = '0,0,0,0,4873,113,0;0,-1,0,1,4763,1101,0;0,0,0,0,4880,113,0;0,-1,0,1,4870,1101,0;0,-1,0,1,4664,1101,0;0,0,0,0,4888,113,0;0,-1,0,1,4754,1101,0;0,0,0,0,4686,113,0;0,-1,0,1,3602,1101,0;'fXT = [1, 32, 32, 0, 0, 0, 0, 4, 0, B5T(), -999999, 18204, 0, 0, 3034, 0, 0, 8, 0, '0', _abck, 39098, '-1', '-1', 30261693, 'PiZtE', 83797, 56, 0, '0', 0, ',', ''].join(',')W1T = ["-100", R1T, '-105', vST, '-108', '', '-101', "do_en,dm_en,t_en", "-110", '', '-117', '', '-109', '', '-102', L1T, '-111', '', '-114', '', '-103', '', '-106', '0,0', '-115', fXT, '-112', html_url, '-119', '-1', '-122', '0,0,0,0,1,0,0', '-123', '', '-124', '', '-126', '', '-127', 8, '-128', ',,', '-131', ',,,', '-132', '', '-133', '', '-70', '-1', '-80', '94', '-90', '9d94de22821c3355a13b27ed05656084f29f5daaa8066edff7b0a320a0df4079', '-116', 0];x1T = ZST(34, [W1T, 2, false])RST = W1T.join(x1T)EST = '7a74G7m23Vrp0o5c947885'lST = 'yC4xvrXgniGeyikKztHA5Q=='RST = Mn(Mn(Mn(Mn(2, x1T), 2), x1T), RST = Mn(Mn(Mn(Mn(Mn(EST, lST), x1T), 24 ^ HY(RST), x1T), RST)));RST = function BST(kST, CST) {var PST;var QST;var fST;var hvT;var TvT = kST.split(',');for (hvT = 0; hvT < TvT.length; hvT++)PST = zY(ZY(CST >> c6T[17], c6T[42]), TvT.length),CST *= c6T[43],CST &= c6T[44],CST += 4282663,QST = zY(ZY(r6T(CST &= c6T[45], 8), c6T[42]), TvT.length),CST *= 65793, CST &= c6T[44], CST += c6T[46], CST &= c6T[45], fST = TvT[PST], TvT[PST] = TvT[QST], TvT[QST] = fST;var dvT;return dvT = TvT.join(','), dvT;}(RST, sST[1]);var UvT = [null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null, null]SvT = ''RST = function KvT(XvT, HvT) {for (var vvT = 0; zn(vvT, 127); ++vvT)zn(vvT, c6T[40]) || Jt(c6T[47], vvT) || Jt(34, vvT) || Jt(92, vvT) ? UvT[vvT] = -1 : (UvT[vvT] = SvT.length,SvT += String.fromCharCode(vvT));for (var zvT = '', VvT = 0; zn(VvT, XvT.length); VvT++) {var AvT = XvT.charAt(VvT), xvT = ZY(r6T(HvT, 8), c6T[42]);HvT *= c6T[43],HvT &= c6T[44],HvT += c6T[46],HvT &= c6T[45];var WvT = UvT[XvT.charCodeAt(VvT)];if ('function' == typeof AvT.codePointAt) {var MvT = AvT.codePointAt(c6T[6]);MvT >= 32 && zn(MvT, 127) && (WvT = UvT[MvT]);}WvT >= 0 && (WvT += zY(xvT, SvT.length),WvT %= SvT.length,AvT = SvT[WvT]),zvT += AvT;}var bvT;return bvT = zvT,bvT;}(RST, sST[0])var GvT = (((((("")["concat"](B5T() - A1T, ","))["concat"](0, ","))["concat"](0, ","))["concat"](1, ","))["concat"](2, ","))["concat"](0);RST = Mn(Mn(Mn(Mn(Mn(Mn(Mn("2;", sST[0]), ";"), sST[1]), ";"), GvT), ";"), RST);return RST
}console.log(U1T("4C0EB5576E56746FEA7E44353E408D11~YAAQR/6Yc5BPnNqLAQAAFFPwLhX7EkI2BZKgs0KasB3v8z1/DXKLlqPjmBokz04h+DYiIl9tIvrKfh9dQt/TeFfljUF+nyZqYk3OFGHYsF0nAp51CGFMES2LeMCS6BV91mOd+E30H9Wm2r84gdtqIG/2xbLNgDBr5G1goDbTWKo4cmQckkVSohHHY/pHJBMWf57Smr1kkqSrpc0eAsKCjoj9efCCjpaTwQ4xH5M90aInNQ4nrGSWkOXwjAiWMCXjKmrCUzAY+pOn1t3iZ7XsTESbLCrD9j/QiWq0Bp2GfHOzGoyurQiyyLXLKTKD3E828pr/GcQOjaSawUW4DLkj/3MYdNj6B7ORTvm2tkZKtQ+goghIFv91U3dRGTAXNehjKWPx7MOQKVHOFYjp14E=~3293492~3355459", '9536F265393639331496ED854EE3E805~-1~YAAQrwrgerSeg92LAQAAo3UkNQt6QJJSDBrga9f5KmTHn9Wdd3SzFcOdHquwxSdmh0HUhJUSMrccC/vqwqr9XLD7ZOrXt/VN967VZr6gy174KqV7m/HOA4ufRJJ/qdwaFdRwWnImEJdtbK4TRWvDjy9XPvtcz1A2+qtmV09bV8DuvO0wAIQD9JJxomFL5+GFgLa97spFGlATFHBz4JLX8oOscnBGv6qOKOQvYZgDhbP0Z6vuuS+NcsbF1IdyVzF3/zs/Yb5F5Tuy6wbiKUd/IAAwoWj9Vg/Y4y5n8mk1OjMIpnd6YB9f3Hnso+26lEqcCidXHYq6i8Zb+KlFVr9IyfYIuhxWZo6/OjYvTtKVLNqzOOB2W/XIdS9CQVvXoAtEnd7gNmFA7gZtCrJDZwYmSdcTo5VVrH/iZ5igXjw/~-1~-1~-1', 'https://www.dhl.com/cn-zh/home.html'));- dhl.py
import execjs
import requests
import reheaders = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
url = "https://www.dhl.com/cn-zh/home/tracking/tracking-ecommerce.html"
params = {"submit": "1","tracking-id": "1232343"
}
response = requests.get(url, headers=headers, params=params)
js_url = 'https://www.dhl.com' + re.findall('/noscript><script type="text/javascript" src="(.*?)"></sc', response.text)[0]cookies = {'_abck': response.cookies.get('_abck'),'bm_sz': response.cookies.get('bm_sz'),'ak_bmsc': response.cookies.get('ak_bmsc')
}
headers = {"referer": "https://www.dhl.com/cn-zh/home/tracking/tracking-ecommerce.html?submit=1&tracking-id=1232343","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
res = requests.get(js_url, headers=headers, cookies=cookies)dd = execjs.compile(open('01-akamai-js代码.js', encoding='utf-8').read()).call('U1T', cookies['bm_sz'], res.cookies.get('_abck'), url)
cookies['_abck'] = res.cookies.get('_abck')
data = {'sensor_data':dd}
headers1 = {"origin": "https://www.dhl.com","referer": "https://www.dhl.com/cn-zh/home/tracking/tracking-ecommerce.html?submit=1&tracking-id=1232343","user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
}
print(js_url)
res1 = requests.post(js_url, headers=headers1, cookies=cookies, json=data)
print(res1.text)