网站发展建设思路哪里有免费的网站推广软件

从1998年第一个电商平台成立至今,已经有25年。
随着数字化经济加快发展,大数据、云计算、物联网及人工智能的进一步应用,近年来电商化采购模式也强势崛起,在企业采购领域掀起革命性的巨浪。
而随着市场需求的变化多样,企业采购的业务场景也在不断拓展。
双11将至,为帮助更多的企业通过数字化采购商城进行降本增效,接下来我们将以多个实际应用场景的视角一起来分析传统采购模式痛点,并探讨解决方案,为正在或即将进行采购数字化转型升级的企业提供参考:
场景一:食品消费企业,如何高效进行非生产性物资采购?
食品与每个人的日常生活息息相关,随着我国经济的迅速发展,以及人们生活节奏的加快与生活理念的转变,食品消费行业迎来了巨大的市场需求。但同时,食品消费行业也是一个竞争十分激烈的行业,建设一个高效、稳定、韧性的采购供应链体系,对于食品企业至关重要。

食品消费行业采购常见的问题:
非生采购物资占据了食品行业很大的采购比例,诸如电商赠品、定制礼品/物料、劳保用品、办公用品、MRO物料、IT设备、软件、宣传推广服务等等,不仅采购品类庞杂,且频次高,其中还涉及部分非标商品,采购复杂度更高,每年采购物料高达数千万。
传统采购模式下,食品企业统采和各办事处分散采购两种不同的采购方式,容易造成流程入口不一,导致多系统手工操作,节点分散,费用管控不易;采购渠道分散,影响选品、比价效率;难以进行采购全过程闭环管理等问题,导致采购的直接成本和间接成本均较高。
解决方案:通过企业智慧采购商城,解决企业内部非生产物资采购的诸多问题
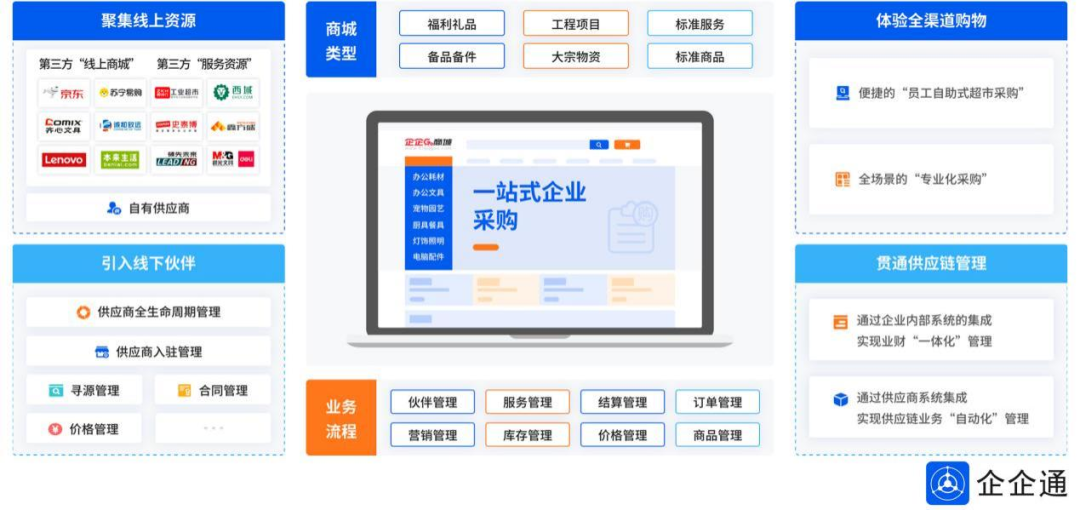
目录式电商化采购,选品更清晰快捷。通过接入京东、苏宁易购、本来生活等第三方电商平台采购资源,满足各个品类采购场景,提供标准商品匹配库,实现目录化采购,各部门人员在线自助式采购,使商品检索和采购流程变得高效、便捷。
统一集采管理,降低企业采购成本。企业可集中分散需求,统一寻源、议价与下单;与此同时,实时追踪从计划、采购到使用各个流程,交易数据即时传递,企业采购透明化,降低非生物资的人力、选品、物流等等综合成本。
采购流程全程可跟踪,采购业务高效透明。商城打通了选品审批、订单、物流、结算等一系列流程,对外可与供应商进行协作,比如需求计划协同、订单合同流转、物流查询、财务对账等等环节,信息及时共享;对内可与ERP、SRM、OA、财务等系统集成,解决各部门数据不一致、数据难以实时同步等问题,有效提升采购效率。
场景二:连锁酒店行业,如何打通端到端智能供应链体系?
酒店行业作为服务业的重要组成部分,一直以来都是投资者关注的热点。我国酒店产业市场规模巨大,随着全球经济的不断发展和人们生活水平的提高,以及旅游业的增长需求,酒店行业规模持续扩张,在这个过程中,采购供应链管理已然成为酒店行业不可忽视的重要力量。

连锁酒店行业采购常见的问题:
连锁酒店企业日常需要采购的物资多而杂,涉及的采购品类主要包括装修、瓷砖、地板、门窗等工程物资,厨房设备、清洁设备、加湿器、门锁、电视、空调等设备物资,以及一次性清洁用品、床垫、饮品、纸巾等运营物资。
对于部分酒店企业而言,有一定信息化建设基础,但普遍较为薄弱,通常以传统手工采购模式为主,通过各个渠道比价采买或由各门店独自采购的方式,导致各方协同效率不高;上游供应商、酒店、旗下子分公司/连锁酒店与同行买家各链路未能打通,难以实现统一管理。
解决方案:搭建B2B商城,打造采购方、供应商、运营三端协同的智能供应链体系
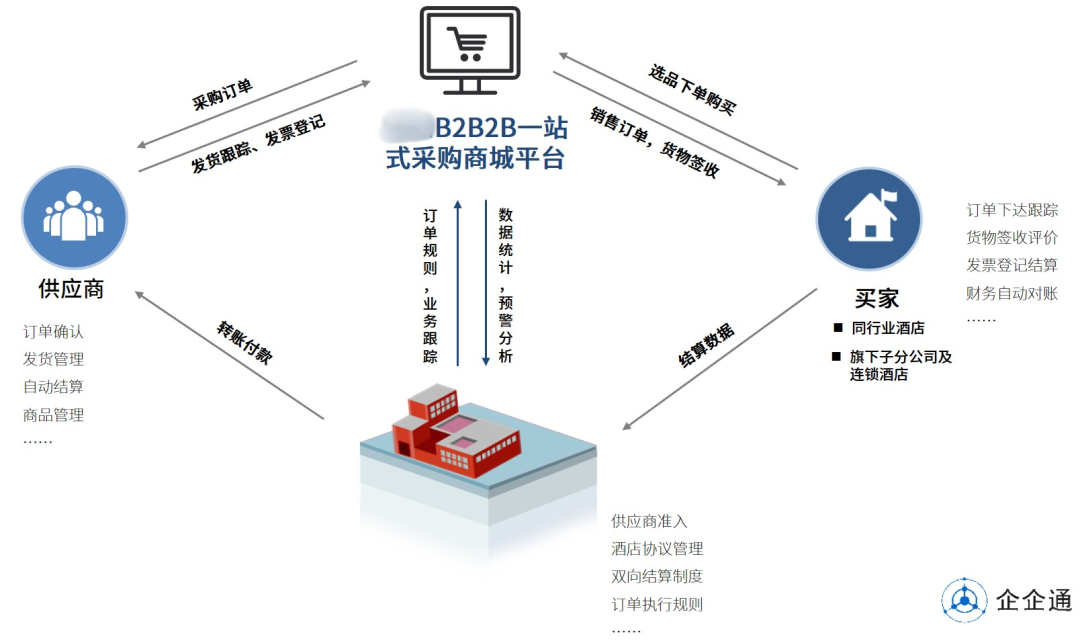
对于酒店:可构建商品、价格、订单、结算等能力中心,规范门店基础数据,对商城平台的订单数据、业务数据进行快速统计分析,并作出预警分析,强化各个连锁酒店装修方案、物料变更、订单及结算的业务管理,提高业务运转效率,更好服务供应商和门店。
对于采购方:旗下子分公司及连锁酒店、同行酒店买家可通过商城平台快速寻源、比价、选品采购、订单、实时跟踪订单物流情况、对货物进行签收评价以及财务自动对账等大大节省了采购时间和成本,使信息标准化、流程规范化,提升采购效率。
对于供应商:工程物资、设备物资、运营物资等上游供应商可通过商城平台进行商品管理、订单确认、发货管理以及自动结算,既提升了供应商的供货能力、财务结算能力,同时企业又可以对热销商品进行预判,进行科学的供货决策。
场景三:电商行业如何有效数据清洗,促成供采撮合交易?
电子商务行业是随着互联网的快速发展而兴起的新型商业模式,如今已经成为全球经济的重要组成部分。电商平台的海量数据中蕴含着丰富的商业信息和价值,如何有效利用这些数据,并将其转化为有价值的洞见和决策依据,一直是电商行业面临的挑战。

电商平台数据管理常见的问题:
由于缺乏有效的数据分析技术、数据质量不高等种种因素,电商企业在数据管理方面存在一定程度上的问题,例如一物多码、多物一码、数据混乱、编码不一致、物料零散等等,给业务实际操作造成各种不便、效率低下。
除此之外,电商企业在进行商品匹配和比价过程中,主要依靠人工操作,不但耗费大量的人力物力与时间成本,在与供应商交流过程中,难以实现实时信息共享,有效沟通。
解决方案:采用聚源池工具打造高质量数据标准库,规范商品与价格管理
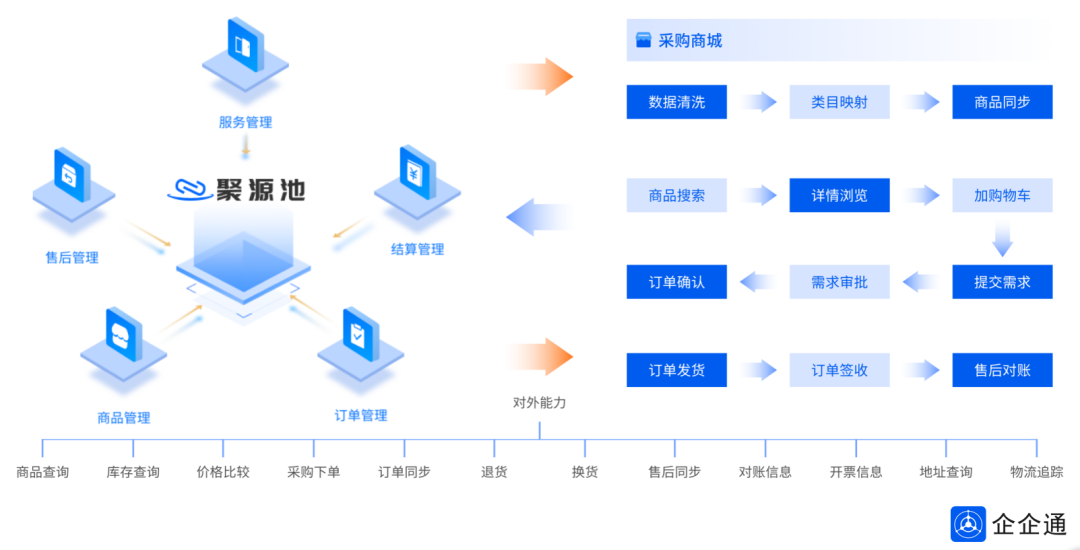
第一,通过聚源池AI智能算法,帮助电商企业快速清洗数据、整理物料,例如清洗不同供应商下,同一品牌同一规格的商品,避免重复混乱,与采购方内部系统交互打通,以此实现数据标准完整、唯一、有效、精确,形成高质量标准数据库。
第二,整合京东、工业超市、鑫方盛、史泰博等多个优质主流电商平台,汇聚450万+商品资源,丰富的商品品类,满足电商企业一站寻源、选品、批量上下架,实现择优采购,促成供采双方撮合交易,提升电商企业对接效率,降低对接成本。
第三,多种线上比价方式,价比三家,便于制定价格,掌握市场价格趋势,省去人工手动多渠道多方式筛选比价,提升效能;同时支持线上智能选品、商品管理等功能,实现用户、采购人员和供应商三端在线高效协同,让采购管理更加智能。
总结:
中国互联网的快速发展和数字化经济进程的加快,使得未来的企业竞争,从供应链的竞争延伸至整个生态系统的竞争。
随着“互联网+”优势不断凸显,商城采购模式高效、快捷、阳光的优势更是显而易见。
企企通以敏锐的触觉及时洞悉企业采购发展趋势,提供企业商城,一方面满足企业内部采购,如福利礼品、办公用品、备品备件、大宗物资等采购场景,另一方面帮助企业对外销售,带动业绩增长。令采购交易过程更规范、更智能,降本提效。
企企通企业商城不仅在食品消费、酒店行业、电商行业得到应用,也能满足高新科技制造、生物医药、能源化工、地产物业等众多行业场景,覆盖面广,未来将赋能更多行业探索新采购数字化场景和模式,推动各个行业全链条的协同优化与价值提升。