免费商城网站源码深圳专业网站开发
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到教程。
我能确定这个工程的接口代码肯定没有问题,这时请求接口依旧报 404。
如:
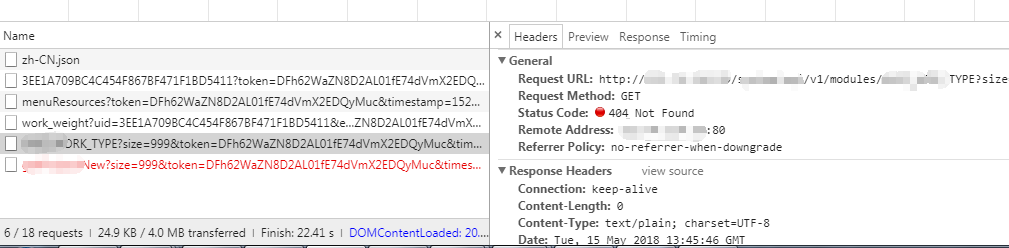
经过多方检查 最终确认问题原因:KONG 网关配置不对。
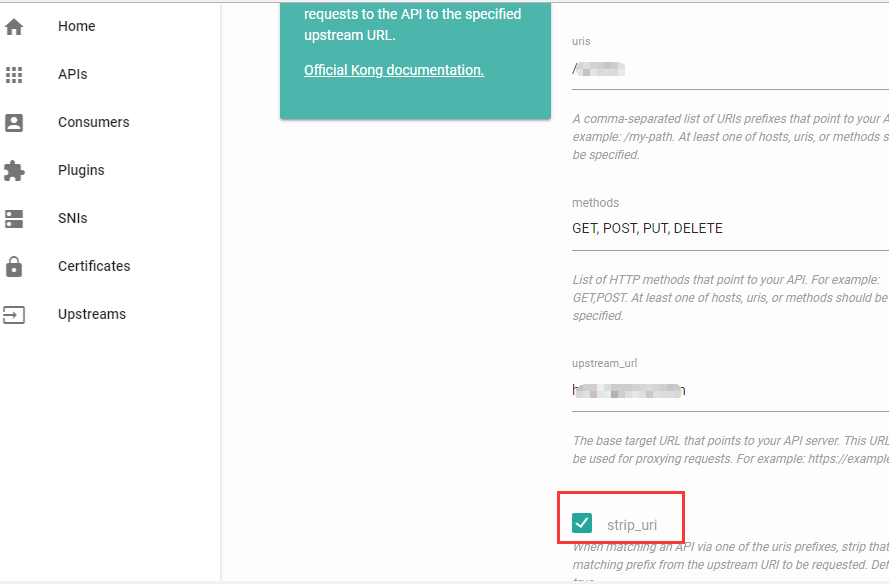
如下图,红框中的不能勾选,去掉勾选接口请求正常。
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到教程。
我能确定这个工程的接口代码肯定没有问题,这时请求接口依旧报 404。
如:
经过多方检查 最终确认问题原因:KONG 网关配置不对。
如下图,红框中的不能勾选,去掉勾选接口请求正常。