做网站建设的前景湖南营销型网站建设推广

目录
1、让任务栏显示“右键菜单”
2、任务栏置顶
3、还原经典右键菜单
4、Win11版任务管理器
5、新版Alt+Tab
6、开始菜单不再卡
7、为Edge浏览器添加云母效果
8、自动切换日/夜模式
Win11在很多地方都做了调整,但由于涉及到诸多旧有习惯,再加上前期Bug的缘故,初上手时让人很不适应。
好在微软的号召力不俗,各种“改装”小工具也是层出不穷。虽然不能解决掉Win11的所有问题,但至少可以让你的Win11用起更顺手!
1、让任务栏显示“右键菜单”
不支持右键,是Win11任务栏中一个最大的“Bug”,日常使用超级不便。
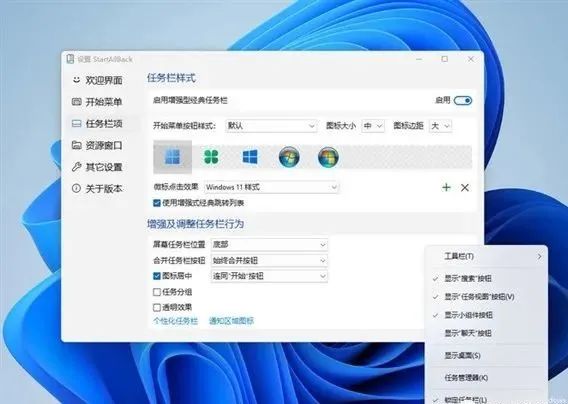
StartAllBack是一款第三方工具,通过点击“任务栏项→启用增强型经典任务栏”,可以快速恢复任务栏的右键菜单功能。
此外它还提供了图标大小、间距调节、任务栏透明等小功能,实用的同时美观度也不错。
2、任务栏置顶
很多小伙伴都喜欢将任务栏放置到屏幕顶端或侧面,但……Win11并不支持。
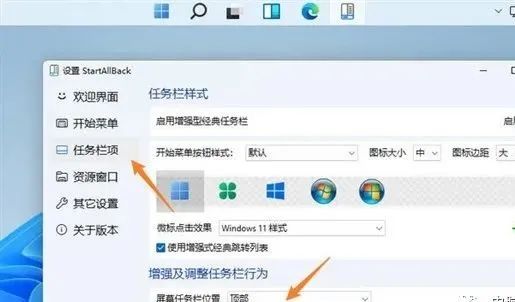
想要解决这个问题,依旧还是利用前面提到的那款StartAllBack,
点击“任务栏项→启用增强型经典任务栏”,修改“屏幕任务栏位置”到喜欢的位置,就可以了。
3、还原经典右键菜单
除了任务栏以外,右键菜单也是Win11中越改越难用的设计之一。想要还原经典的右键菜单模样,除了使用工具软件外,你也可以通过在Windows终端中输入几行代码快速实现。
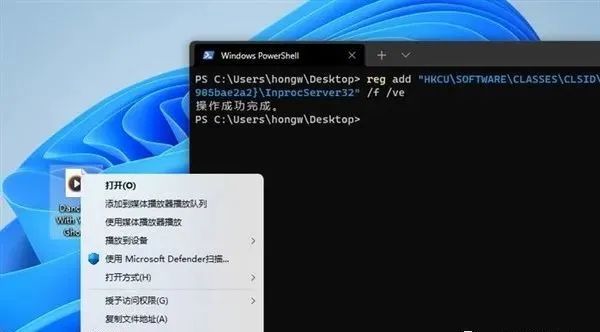
首先,在桌面空白部位右击鼠标,选择“在Windows终端中打开”;
然后,将下列代码复制进去:
reg add "HKCU\SOFTWARE\CLASSES\CLSID\{86ca1aa0-34aa-4e8b-a509-50c905bae2a2}\InprocServer32" /f /ve
回车确定后,再次打开任务管理器,右击“Windows资源管理器”并选择“重新启动”即可;

4、Win11版任务管理器
任务管理器是Windows中为数不多的N年未更新的系统组件之一,现在借助一款名叫ViveTool的小工具,你可以提前体验一下最新版的Win11任务管理器。
首先,将Win11升级至Dev频道Build 22538,并下载好最新版ViveTool 0.2.1;
然后,打开ViveTool文件夹,在窗口空白部位右键选择“在Windows终端中打开”;
接下来,顺序输入以下命令:
.\vivetool addconfig 35908098 2
.\vivetool addconfig 37204171 2
.\vivetool addconfig 36898195 2
重新启动电脑后,任务管理器就会升级到全新版本。

注:新版Win11任务管理器尚处于预览阶段,很多功能并未适配。目前已有网友发现该版本存在稳定性问题,在官方未提供处理结果前,暂时只能进行回滚处理,请大家谨慎开启。
5、新版Alt+Tab
除了新版任务管理器外,Win11也带来了全新的Alt+TAB外观。
与初版的全屏式设计不同,新版Alt+Tab还原了Win10的窗口化设计,同时又融合上最新的“云母Mica”特效,看起来“果”味十足!

首先,将Win11升级至Dev频道Build 22526以上,同时下载好最新版ViveTool 0.2.1;
然后,打开ViveTool文件夹,在窗口空白部位右键选择“在Windows终端中打开”;
接下来,输入命令:
.\vivetool addconfig 36226836 2
重新启动电脑后,Alt+Tab便成功美颜了!
6、开始菜单不再卡
无论是资源管理器还是开始菜单,Win11给人的感觉总是有那么一点点卡顿。
很多人认为这是由于Win11的底层代码优化不佳所致,其实真正导致Win11卡顿的是因为它在打开这些位置时,会自动检索一遍Office.com里的内容。
而这种联网式操作原本就会导致反应速度减慢,更何况国内访问Office.com一直都不是很通畅。

要想解决这个问题,我们可以通过调整组策略加以搞定。
具体方法是:点击开始菜单,输入“gpedit.msc”打开组策略编辑器。然后依次定位到“计算机配置→Windows设备→管理模板→Windows组件→文件资源管理器”。
双击右侧“在‘快速访问’视图中关闭Office.com的文件”,将默认的“未配置”修改为“已禁用”。重新启动电脑后,你会发现资源管理器和开始菜单在打开操作上,将比以前更流畅。
7、为Edge浏览器添加云母效果
由于种种原因,Win11版Edge浏览器并没有加入全新的“云母Mica”特效,其实只要我们在地址栏中输入“edge://flags”,搜索“mica”。
然后将第二项“Enable Windows 11 Mica effect in title bars”设置为“Enabled”。重新启动浏览器后,漂亮的云母特效便出现了。

8、自动切换日/夜模式
Win11的黑暗模式要比Win10好很多,但现实的问题是,它只能由用户手动切换,实际使用中并不方便。
Auto Dark Mode是一款自动切换Windows模式的小工具,启动后首先将“时间”调整为“日出至日落”,然后点击“个性化→选择壁纸”,分别为浅色与深色主题设置不同色彩的壁纸。
点击确定后,即可实现Win11的自动切换日/夜效果。同时这款小工具还提供了玩游戏与未充电模式下的自动切换开关,感兴趣的小伙伴不妨试一试。

写在最后
Win11已经发布很长时间,但由于各种各样的问题,大家对于它的兴趣似乎一直不大。
随着微软对Win11优化力度不断增加,未来Win11相信会变得越来越理想,但至少目前这些小工具还是我们的不二之选。