网站开发简介ifttt wordpress
我的windows11系统上,之前已经安装好了window版本的docker,没有安装的小伙伴需要去安装一下。
下面直接记录安装linux的步骤:
一、创建linux容器
1、拉取镜像
docker pull ubuntu
2、查看镜像
docker images
3、创建容器
docker run --name ssh_ubuntu -t -i -d -p 3316:22 -v D:\docker\DataSet:/home/DataSet -v D:\docker\Project:/home/Project ubuntu
4、进入容器
docker exec -it 容器ID bash![]()
二、在linux上安装ssh服务
安装后可以使用ssh登录linux
1、更新apt-get
apt-get update
2、安装ssh
apt-get install openssh-client
apt-get install openssh-server

3、启动ssh服务
/etc/init.d/ssh start![]()
查看ssh服务是否启动
ps -e|grep ssh![]()
4、修改sshd_config文件
1)、安装vim工具
apt-get install vim
2)、编辑sshd_config文件
vim /etc/ssh/sshd_config添加一行数据:
PermitRootLogin yes3)、重启ssh服务
service ssh restart![]()
4)、设置root用户密码
passwd root
三、ssh链接测试
1、连接
ssh root@localhost -p 33162、进入到home目录使用ls查看
cd /home
ls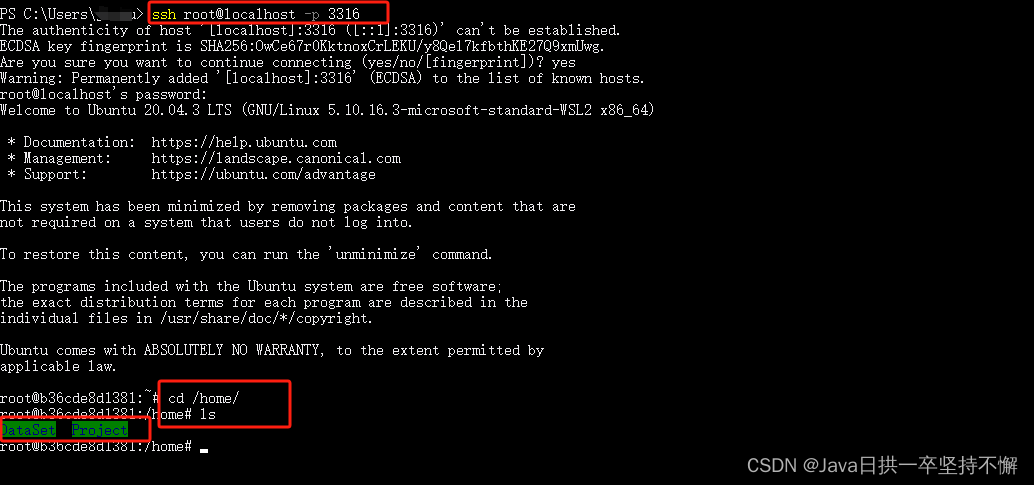
/home目录下的DataSet和Project就是挂载目录,方便存放数据和代码
至此,linux安装完成了.
四、将需要的文件从window系统复制到对应docker容器中的linux系统里
1、先将需要的文件放到window的某个文件夹中
2、使用docker命令查看要复制到的linux的容器id
docker ps
3、使用docker命令将文件从window复制到linux
docker cp 文件 容器ID:/home这里实际操作命令如下:
docker cp .\yum-3.4.3.tar.gz b36cde8d1381:/home