为什么网站目录不收录网站老提示有风险
源码介绍:
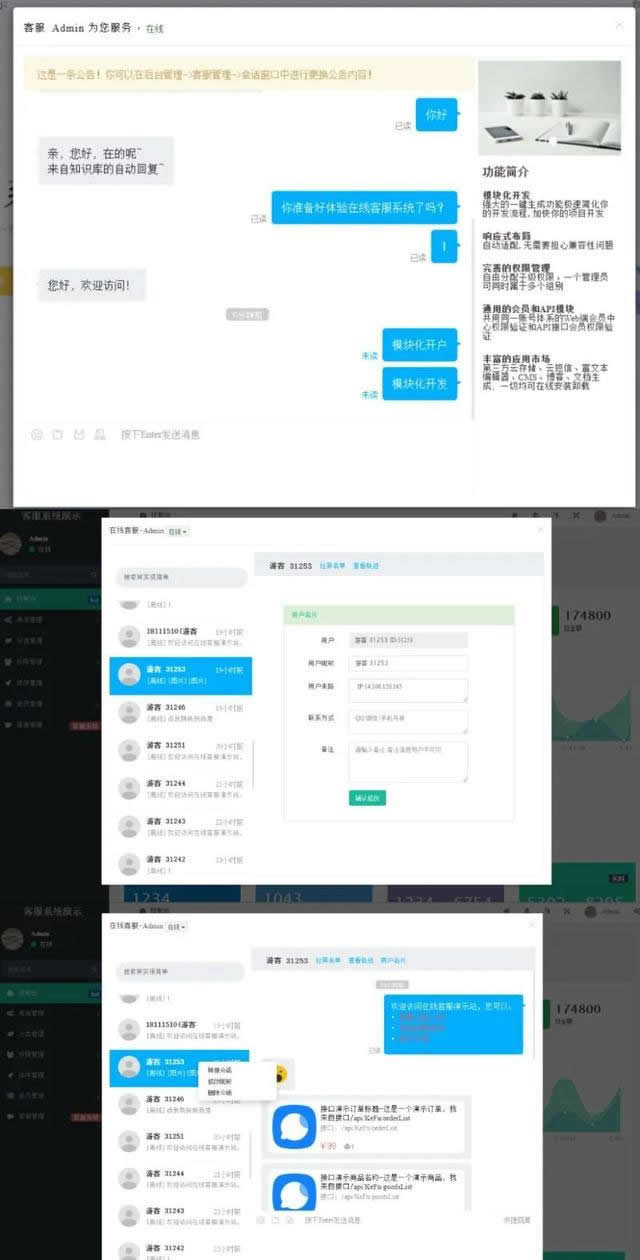
Workerman在线客服系统源码。
workerman是一个高性能的PHP socket 服务器框架,workerman基于PHP多进程以及libevent事件轮询库,PHP开发者只要实现一两个接口,便可以开发出自己的网络应用,例如Rpc服务、聊天室服务器、手机游戏服务器等。
本源码特点:
模块化开发
强大的一键生成功能极速简化你的开发流程,加快你的项目开发
响应式布局
自动适配,无需要担心兼容性问题
完善的权限管理
自由分配子级权限、一个管理员司同时属于多个组别
通用的会员和API模块
共用同一账号体系的Web端会员中心权限验证和API接口会员权限验证
丰富的应用市场
第三方云存储、云短信、富文本编辑器CMS博客文档生成,一切均可在线安装卸载
简单搭建了下,能搭建出来,但时间比较紧。此版本没有uniapp端源码,因为在线客服系统感觉用不上uniapp端源码。就没测试客服代码
源码下载:百度网盘