中企动力公司网站价格网站制作建设公司推荐
在上一篇文章《内核取ntoskrnl模块基地址》中我们通过调用内核API函数获取到了内核进程ntoskrnl.exe的基址,当在某些场景中,我们不仅需要得到内核的基地址,也需要得到特定进程内某个模块的基地址,显然上篇文章中的方法是做不到的,本篇文章将实现内核层读取32位应用层中特定进程模块基址功能。
上一篇文章中的PPEB32,PLIST_ENTRY32等结构体定义依然需要保留,此处只保留核心代码,定义部分请看前一篇文章,自定义读取模块基址核心代码如下,调用GetModuleBaseWow64()用户需传入进程的PROCESS结构该结构可通过内核函数PsLookupProcessByProcessId获取到。
对于函数内部执行过程如下:
- 1.根据传入的
EProcess结构调用KeStackAttachProcess附加到该进程内。 - 2.调用内核函数
PsGetProcessWow64Process此函数可得到该进程空间内PEB结构数据。 - 3.通过for循环遍历整个
pPeb->Ldr链表,并在遍历过程中通过RtlEqualUnicodeString判断是否是我们需要的模块。 - 4.如果判断是我们需要取出的模块名,则将
LdrEntry->DllBase取出,此处取出的基地址也即是我们所需要的。 - 5.比较结束后,通过调用
KeUnstackDetachProcess这个内核模块脱离进程空间。
ULONGLONG GetModuleBaseWow64(_In_ PEPROCESS pEProcess, _In_ UNICODE_STRING usModuleName)
{ULONGLONG BaseAddr = 0;KAPC_STATE KAPC = { 0 };KeStackAttachProcess(pEProcess, &KAPC);PPEB32 pPeb = (PPEB32)PsGetProcessWow64Process(pEProcess);if (pPeb == NULL || pPeb->Ldr == 0){KeUnstackDetachProcess(&KAPC);return 0;}for (PLIST_ENTRY32 pListEntry = (PLIST_ENTRY32)((PPEB_LDR_DATA32)pPeb->Ldr)->InLoadOrderModuleList.Flink;pListEntry != &((PPEB_LDR_DATA32)pPeb->Ldr)->InLoadOrderModuleList; pListEntry = (PLIST_ENTRY32)pListEntry->Flink){PLDR_DATA_TABLE_ENTRY32 LdrEntry = CONTAINING_RECORD(pListEntry, LDR_DATA_TABLE_ENTRY32, InLoadOrderLinks);if (LdrEntry->BaseDllName.Buffer == NULL){continue;}// 当前模块名链表UNICODE_STRING usCurrentName = { 0 };RtlInitUnicodeString(&usCurrentName, (PWCHAR)LdrEntry->BaseDllName.Buffer);// 比较模块名是否一致if (RtlEqualUnicodeString(&usModuleName, &usCurrentName, TRUE)){BaseAddr = (ULONGLONG)LdrEntry->DllBase;KeUnstackDetachProcess(&KAPC);return BaseAddr;}}KeUnstackDetachProcess(&KAPC);return 0;
}
如上就是如何得到特定模块基址的方法,如下是入口函数的调用方法,首先通过传入6164这个PID号,得到进程EProcess结构,其次使用RtlInitUnicodeString(&unicode, wchar_string)初始化得到kernel32.dll字符串,最终调用GetModuleBaseWow64函数获取到进程6164中kernel32.dll的模块基地址信息。
VOID UnDriver(PDRIVER_OBJECT driver)
{DbgPrint("驱动卸载成功 \n");
}NTSTATUS DriverEntry(IN PDRIVER_OBJECT Driver, PUNICODE_STRING RegistryPath)
{DbgPrint(("hello lyshark \n"));PEPROCESS pEProcess;HANDLE PID = (HANDLE)6164;// 初始化字符串UNICODE_STRING unicode;wchar_t *wchar_string = L"kernel32.dll";RtlInitUnicodeString(&unicode, wchar_string);// 取模块句柄PsLookupProcessByProcessId((HANDLE)PID, &pEProcess);ULONGLONG base32 = GetModuleBaseWow64(pEProcess, unicode);DbgPrint("ModuleBaseAddress: 0x%X \n", base32);Driver->DriverUnload = UnDriver;return STATUS_SUCCESS;
}
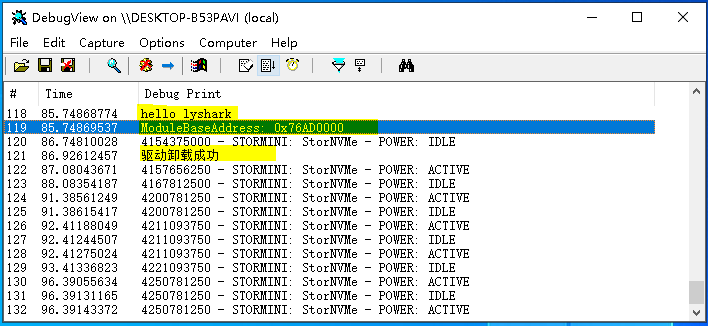
这段代码输出效果如下所示: