一、Spring的组成
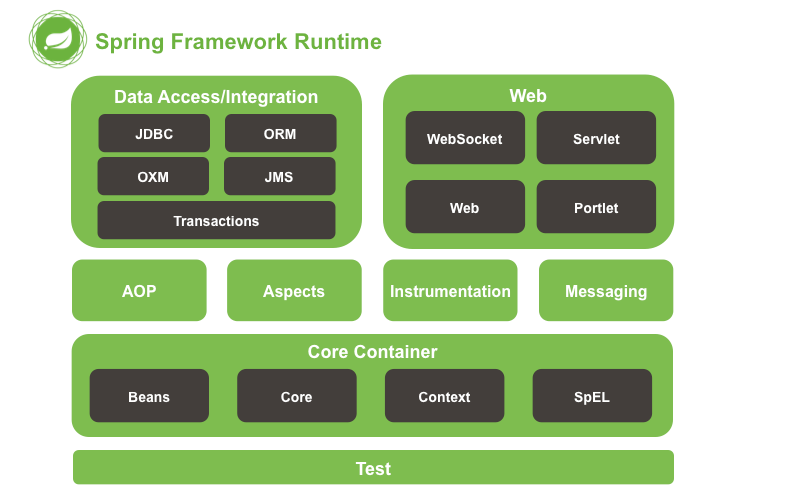
其中最核心的是Core Container核心容器
二、spring框架的作用:
对于我目前了解的spring框架,其中一个作用是用来降低程序间的耦合度的,也就是降低程序间的依耐性。
IOC:inversion of control 控制反转-->即将app和资源分开,通过一个工厂来联系,将app中想要获得资源的控制权交给了工厂,所以叫做控制反转
即对象的创建通过spring在读取配置文件(或进行注解扫描)时就进行创建(单例模式),而程序需要用到对象时就从spring容器中取,从而降低了两个程序间的依赖关系
DI:Dependency Injection 依赖注入-->在当前类需要用到其他类的对象,用spring为我们提供,我们只需要在配置文件中说明,依赖关系的维护:称为依赖注入
即在创建了一个对象中含有另外一个类对象,此时就需要依靠spring框架给该对象进行对象实例的注入。以避免在该类中进行对象创建增加耦合度
注入方式:
使用构造函数提供:
bean内部使用标签<constructor-arg>:
index,name,type:都是指定赋值的对象
value:是用于提供基本数据类型和String的数据
ref:用于指定其他bean类型的数据.指bean容器中有的
使用set方式提供:
bean内部使用property标签:
name:是set方法名称
value:值
使用注解提供:
用于创建对象的注解:
@Component:用于把当前类对象存入spring容器中 value属性指定id(默认为当前类名,首字母小写)
@Controller(表现层),@Service(业务层),@Repository(持久层) 和Component注解的属性和作用一样,是spring框架对三层对象提供
用于注入数据的注解:
@Autowired:自动按照类型注入,只要容器中有唯一的一个bean对象类型和要注入的变量类型匹配,就可以注入成功
出现的位置:可以是变量上,也可以在方法上
多个匹配时:会根据变量名称匹配id,若不匹配报错
@Qualifier:在按照类型注入的基础之上再按照名称注入.在给类成员注入时不能单独使用,但在个方法参数注入时可以
属性:value(注入的id)
@Resource:直接按照bean的id注入
属性:name(注入的id)
以上三个都只能注入bean对象,基本类型和String类型无法使用上述注解实现
集合:只能通过XML来注入
@Value:用于注入基本类型和Stirng类型
属性:value(用于指定值,可以用spring中的SpEl(也就是spring的el表达式))