长沙银狐做网站wordpress 一句话木马
uni-app框架:使用Vue.js开发跨平台应用的前端框架,编写一套代码,可编译到Android、小程序等平台。
框架支持:springboot/Ssm/thinkphp/django/flask/express均支持
前端开发:vue.js
可选语言:python+java+node.js+php均支持
运行软件:idea/eclipse/vscode/pycharm/wamp均支持
数据库 mysql
数据库工具:Navicat/SQLyog都可以 小程序Android端运行软件 微信开发者工具/hbuiderx
原生wxml开发对Node、预编译器、webpack支持不好,影响开发效率和工程构建。所以都会用uniapp框架开发
前后端分离,后端给接口和API文档,注重前端,接近原生系统
学校图书馆为了方便管理图书,开发一款图书馆APP管理软件就能实现大规模的管理,学生们在借用图书的时候也能方便使用。学生使用该款软件也能实现实时的观察借书的到期时间,合理的利用借书的时间段。图书馆的资源是为全体师生服务的,里面的书籍资源丰富,也有针对学生的专属空间。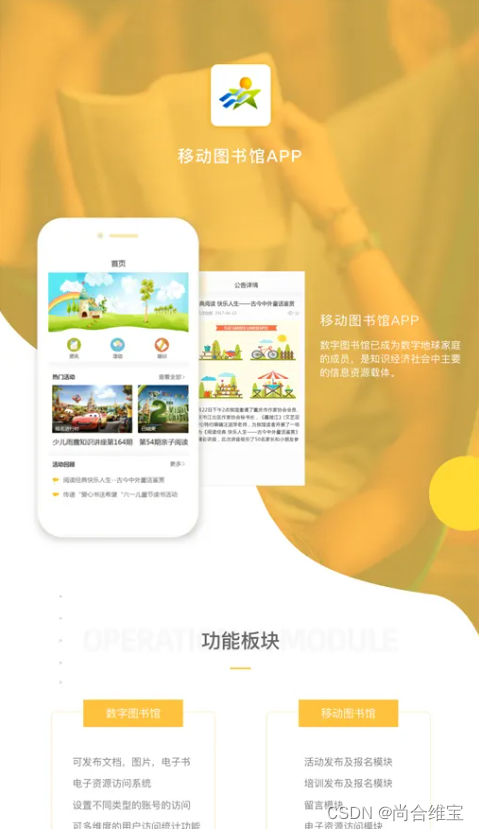
传统的图书馆在互联网的影响下也开始慢慢的向智能化转变,借助图书馆app软件可以帮助学生线上管理相关的借书方案,信息化时代,这样的管理方案不单可以为全体师生带来方便,也能很好的为线上的用户提供服务。
大学的图书馆每天都有人,许多的学生,老师在图书馆学习,有的是学习有的是看书。整体的图书馆也能提高工作效率,让学生感受到有成就感,认可图书馆的模式,图书馆APP软件主要功能就是为学生提供服务,让学生使用智能终端进行各种各样的操作,实现各项步骤,流程的便利。
针对图书馆的各项管理制度,流程等需求,对书籍的信息管理实现了各类的关联,从而实现线上的控制。图书馆APP软件可以简化全体师生的借书服务流程,提供精准的管理方式。如果对图书管理软件有问题的话可以线上咨询我们,以上就是关于图书馆APP软件的特点,开发制作流程。
版权声明:本文作者由尚合维宝原创文章,著作权归作者所有,转载请告知作者并注明出处