园区做网站的好处网站解析慢 优化
目录
一、概念题
1.区域的概念、类型、特性
2.区域分析的概念、主要内容
3.自然环境、自然资源的概念
4.区域自然资源评价的内容
5.可持续发展理论定义
6.经济增长、经济结构定义
7.产业结构概念
8.人口增长分析的含义、指标
9.技术进步概念、类型
10.技术进步对区域发展影响
11.科技论文、专利、科技成果定义
12.绿色GDP、人类发展指数
13.区域优势概念、特征
14.城市竞争力评价体系分类
15.区域规划概念、内容、分类
16.区域规划工作步骤
17.区位论概念
18.可持续发展理论核心内容
19.循环经济的概念
20.点-轴开发模式积极意义及其问题
21.区域发展战略概念 区域发展定位概念 战略目标定义
22.土地资源概念
23.四种综合分区 长株潭七种分区
24.土地利用规划基本内容
25.城镇体系概念及类型
26.我国城镇体系规划的任务
27.城镇体系规划编制的程序
28.城镇化发展战略的目标
29.新型城镇化五个方面和三个重难点
30.区域自然灾害定义、类型
二、简答题
1.简析“稻一鱼一鸭”综合种养模式被称为科学化生态系统的原因?
2.说明从江县侗乡发展“稻一鱼一鸭”综合种养模式的自然部区位优势
一、概念题
1.区域的概念、类型、特性
区域是一个空间概念,是依一定的目的、准则在地球表面上划定的一个空间范围,它以某些物质或非物质客体特征而区别于其他空间范围。
类型:
①均质区域:区域内部某些或某种特性存在一致性和相似性,并以这些一致性或相似性区别于其他区域,我们将具有这些特性的区域称为均质区域。
②结节区域:区域内各异质要素或异质空间存在高度关联性,共同构成一个具有某种功能的空间有机体,此类区域即结节区域,又称功能区域或枢纽区域。
特性:
①整体性(或系统性):区域内各组成要素间通过相互联系、渗透、融合形成一个具有强烈内在联系的统一整体,即区域的整体性。
②结构性:区域的结构性是指构成区域的各要素间存在着包括空间位置、功能联系、作用地位等方面的关系,如区域城乡结构、城镇体系结构、经济地域结构等。
③动态性:由于构成区域的要素自身及其相互作用关系、区域外围环境等的变化,导致区域本身发生变化的特征。
2.区域分析的概念、主要内容
区域分析主要是对区域发展的自然条件和社会经济背景特征及其对区域发展的影响进行分析,以探讨区域内部各自然要素及人文要素间和区域间相互联系的规律。
主要内容:①区域发展条件分析②区域发展状况评价与问题诊断③区域发展方向及策略分析。
3.自然环境、自然资源的概念
自然环境是人类生存和发展所必需的自然条件和自然资源的总和,是由岩石、土壤、水、大气、生物等自然要素有机结合而形成的自然综合体。
自然资源是指存在于自然界,可以被人类利用并能产生经济或社会价值的自然环境因素。
4.区域自然资源评价的内容
①自然资源量的评价②自然资源质的评价③自然资源地理分布特征与地域组合特征的评价④自然资源开发利用方案的评价⑤自然资源开发利用效应的评价。
5.可持续发展理论定义
可持续发展是指既满足当代人的需要,又不对后代人满足其需要的能力构成危害的发展。
6.经济增长、经济结构定义
经济增长:通常是指一定时间内(通常是一年)一个国家或区域总产出的增加,用货币形式表示就是国内生产总值的增加,用实物形式来表示,就是各种产品生产总量的增加。
经济结构:是指国民经济的组成和构成,涵盖生产、流通、分配、消费各个环节的要素组成或构造。
7.产业结构概念
产业结构,亦称国民经济的部门结构,是国民经济各产业部门之间及各产业部门内部的构成。
8.人口增长分析的含义、指标
人口增长包括自然增长和机械增长,人口自然增长分析是指在总结当前及历史时期区域人口自然增长的特征和规律的基础上,预测未来区域人口自然增长的趋势,而人口机械增长是指人口的净迁移状况,以机械增长率表示。
自然增长指标:出生率、死亡率、自然增长率、育龄妇女生育率等
机械增长指标:机械增长率
9.技术进步概念、类型
技术进步是指通过科学技术来扩大并深化对客观世界的认识,进而改造自然,使之更好地满足人类社会的物质和精神需求所取得的进化与革命。
类型:
①广义的技术进步包括“软”“硬”两种技术在内的整个科学技术的进步,是指技术所涵盖的各种形式知识的积累与改进,特别是其中与经济发展关系密切的工程技术、管理水平、决策水平及智力水平等软技术的发展。
②狭义的技术进步指工程技术即所谓的“硬技术”的发展与提高,主要指生产工艺、中间投入品及制造技能等方面的革新和进步。
10.技术进步对区域发展影响
技术进步可以提高自然资源利用效率、技术进步可以促进区域经济发展、技术进步可以改变区域劳动就业。
11.科技论文、专利、科技成果定义
科技论文是科学研究活动的重要产出形式。
专利是专利权的简称,是知识产权的一种。
科技成果即科学技术研究成果,是指为解决某一科学技术问题,经过研究、实验、试制等创造性活动,并经过实践检验获得社会承认,具有一定新颖性、先进性和实用价值(或理论价值)的结果或重大项目的阶段性成果。
12.绿色GDP、人类发展指数
绿色GDP=传统GDP-自然环境部分的虚数-人文部分的虚数。用以衡量扣除因发展所造成的自然和人文资产损失后新创造的真实国民财富数量
人类发展指数:用预期寿命、教育水准和生活质量等三项基础变量,按照一定的计算方法,计算综合指标。
13.区域优势概念、特征
区域优势,是指某个区域在其发展过程中所具有的特殊有利条件。由于这些条件的存在使该区域更富有竞争能力,具有更高的资源利用效率,从而使区域的总体效益保持在较高水平。
特征:①普遍性、②相对性、③动态性
14.城市竞争力评价体系分类
①中国城市竞争力研究会指标体系,涵盖经济、社会、环境、文化四大系统。②中国社会科学院财经战略研究院指标体系,包括8个一级因子,27个二级因子。③城市竞争力评价的“弓弦模型”,认为城市竞争力应是城市综合竞争力,综合竞争力是各个分力的耦合,包含硬分力和软分力。
15.区域规划概念、内容、分类
区域规划是一定时期内对一定地域范围的经济、社会发展建设、土地利用和生态环境保护的总体部署。
内容:①区域发展战略②区域土地利用与保护③区域产业规划布局④区域基础规划⑤区域城镇体系规划⑥区域生态环境保护规划⑦区域防灾减灾规划⑧区域管理与区域政策
分类:
按体制环境划分:①强调控模式②弱调控模式③多元调控模式
按规划属性划分:①行政区②自然区③经济区④社会区
按规划内容侧重点划分:①物质性的区域规划②策略性区域规划③综合性的区域规划
按划分功能属性划分:①开发性规划②保护性规划③协调性规划
16.区域规划工作步骤
①区域发展现状调查与资料收集②确定区域发展目标③区域发展的专题与对策研究④规划方案设计⑤规划方案评估⑥报批定案⑦实施阶段
17.区位论概念
区位论也称为区位理论,是研究经济行为的空间选择的理论,或者说是研究经济活动最优地点的理论。
18.可持续发展理论核心内容
一是代际间发展的公平性,二是区域间发展的公平性,三是社会经济发展与人口、资源、环境间的协调性。
19.循环经济的概念
循环经济是指以“减量化”、“再使用”、“资源化”为操作原则(称为3R原则),以“低消耗、低排放、高效率”为特征的经济发展模式。
20.点-轴开发模式积极意义及其问题
意义:①有利于发挥集聚经济的效果②能够充分发挥各级中心城镇的作用③有利于把经济开发活动结合为有机整体④有利于区域开放式发展
问题:①比较适用于开发程度低、尚未奠定经济布局框架的国家和地区。②轴线和据点的等级划分,尚未有明确的标准和原则,带有一定的主观随意性。
21.区域发展战略概念 区域发展定位概念 战略目标定义
区域发展战略是对区域整体发展的分析、判断而做出的重大的、具有决定全局意义的谋划。
区域发展定位是指判断与表述区域在劳动地域分工中所占据的地位、所起的作用和所承担的功能。
区域发展目标即战略目标,是区域发展战略的核心,是战略思想的集中反映,它是指战略期限内区域发展方向和要达到的理想状态。
22.土地资源概念
土地资源是指在土地总量中,现在和可以预见的未来。能为人类利用的土地。
23.四种综合分区 长株潭七种分区
①都会区②市镇密集区③开敞区④生态敏感区
①综合功能区②产业园区③CBD地区④科教创新发展区⑤绿心创新发展区⑥生态保育区⑦高品质乡村地区
24.土地利用规划基本内容
①确定土地利用目标②确定土地利用指标③土地利用分区与用地配置④建设工程布局与用地规划⑤制定土地利用规划⑥拟定规划实施措施
25.城镇体系概念及类型
是指在一定地域范围内,以中心城市为核心,由一系列不同等级规模、不同职能分工、相互密切联系的城镇组成的有机整体。
①以中心城市数量多寡组合方式可以分为:a.单中心体系类型b.多中心城镇体系类型。
②按区域的经济类型,可以分为综合经济区型、矿区型、农业区型、工业区型等。
③按行政等级和管辖范围,可以分为全国、省域、市域、县域及跨行政区的城镇体系类型,此外,还有以特殊的地理区域和经济区域为对象的,如沿海、沿江、沿线、边境地区城镇体系类型等。
26.我国城镇体系规划的任务
城镇体系规划的任务是:综合评价城镇发展条件,制定区域城镇发展战略,预测区域人口增长和城镇化水平,拟定各相关城镇的发展方面与规模,协调城镇发展与产业配置的时空关系,统筹安排区域基础设施和社会设施,引导和控制区域城镇的合理发展与布局,指导城市总体规划的编制。
主要任务是主导城乡空间结构调整,指导区域性基础设施配置,引导生产要素流动、集聚。
27.城镇体系规划编制的程序
①规划工作准备阶段②实地调查阶段③资料分析和专题研究阶段④发展预测阶段⑤规划方案的构思和规划大纲编写、论证阶段⑥规划方案的拟定和规划评审稿编写、论证阶段⑦上报审批阶段。
28.城镇化发展战略的目标
①城镇化的速度和现代化水平。一般认为,城镇化水平在30%以下,为城镇化低速增长时期;城镇化水平在30%-70%,为城市快速增长时期;当城镇化水平在70%以上时,又进入城市稳定增长时期。
②城镇化质量。如果以城镇人口占总人口的比重来衡量城镇化的指标,那么城市现代化和城乡一体化程度是衡量城镇化质量的方面。
29.新型城镇化五个方面和三个重难点
①人的城镇化:农业转移人口市民化,城镇基本公共服务常住人口全覆盖;②“四化”互动的城镇化:面向内需、创新驱动的新兴产业和现代农业互动发展的产业体系;③布局合理的城镇化:城市群、中小城市、小城镇联动发展,城乡规划、基础设施、公共服务等一体化;④生态文明的城镇化:集约、智能、绿色、低碳,促进生产空间集约高效、生活空间宜居适度、生态空间山清水秀;⑤弘扬文化的城镇化:建设公共文化设施,弘扬中华优秀传统文化。
重点和难点:一是人的城镇化,关键是户籍制度改革。二是土地制度改革,关键是农村土地制度改革。三是“城市群”战略。
30.区域自然灾害定义、类型
自然灾害指自然界中致灾因子发生异常现象
类型:①气象灾害②地质灾害③海洋灾害④生物灾害
二、简答题
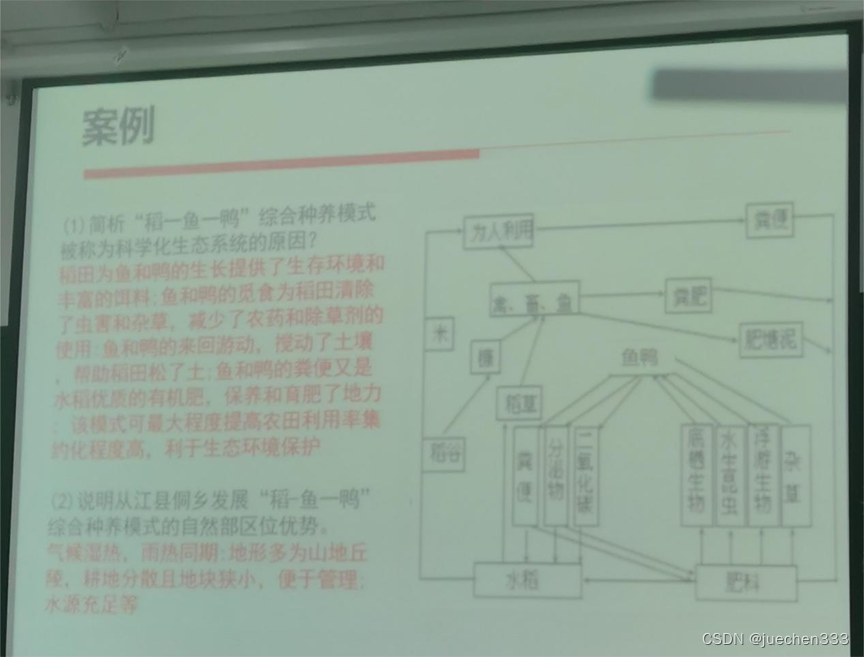
1.简析“稻一鱼一鸭”综合种养模式被称为科学化生态系统的原因?
稻田为鱼和鸭的生长提供了生存环境和丰富的饵料;鱼和鸭的觅食为稻田清除了虫害和杂草,减少了农药和除草剂的使用:鱼和鸭的来回游动。搅动了土壤,帮助稻田松了土:鱼和鸭的粪便又是水稻优质的有机肥,保养和育肥了地力;该模式可最大程度提高农田利用率集约化程度高,利于生态环境保护。
2.说明从江县侗乡发展“稻一鱼一鸭”综合种养模式的自然部区位优势。
气候湿热,雨热同期:地形多为山地丘陵,耕地分散且地块狭小,便于管理;水源充足等。