天台县网站建设哪家好商城网站要怎样建设
作者简介:大家好,我是未央;
博客首页:未央.303
系列专栏:牛客面试必刷TOP101
每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!!!
文章目录
前言
一、删除有序链表中重复的元素-I
题目描述
解题分析
二、二分查找-I
题目描述
解题分析
总结

前言
今天是我们第4天的牛客面试必刷TOP101,比较简单,一定要好好掌握清楚;每天见!!!
一、删除有序链表中重复的元素-I
题目描述
描述
删除给出链表中的重复元素(链表中元素从小到大有序),使链表中的所有元素都只出现一次
例如:
给出的链表为1→1→2,返回1→2.
给出的链表为1→1→2→3→3,返回1→2→3.
数据范围:链表长度满足 0≤n≤100,链表中任意节点的值满足 ∣val∣≤100;
进阶:空间复杂度O(1),时间复杂度O(n)
示例1:
示例2:



解题分析:
解题思路:
本题既然我们要删除重复的元素,那么我们选择采用遍历删除的方法;
思路:
既然连续相同的元素只留下一个,我们留下哪一个最好呢?当然是遇到的第一个元素了!
代码实现:
if(cur.val == cur.next.val)
cur.next = cur.next.next;因为第一个元素直接就与前面的链表节点连接好了,前面就不用管了,只需要跳过后面重复的元素,连接第一个不重复的元素就可以了,在链表中连接后面的元素总比连接前面的元素更方便嘛,因为不能逆序访问。
解题步骤:
- step 1:判断链表是否为空链表,空链表不处理直接返回。
step 2:使用一个指针遍历链表,如果指针当前节点与下一个节点的值相同,我们就跳过下一个节点,当前节点直接连接下个节点的后一位。
step 3:如果当前节点与下一个节点值不同,继续往后遍历。
step 4:循环过程中每次用到了两个节点值,要检查连续两个节点是否为空。
代码编写:



二、二分查找-I
题目描述:
描述:
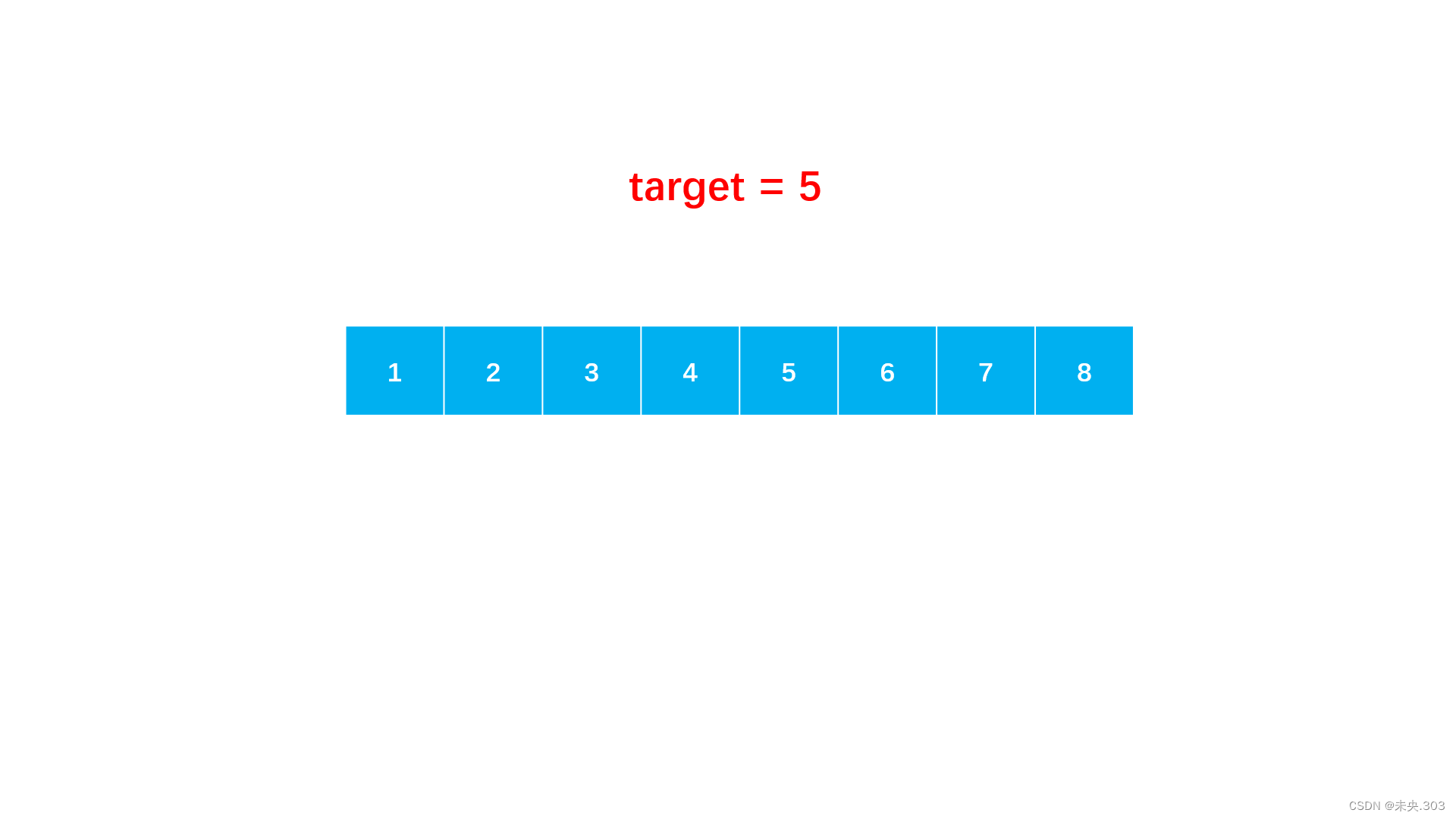
请实现无重复数字的升序数组的二分查找
给定一个 元素升序的、无重复数字的整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标(下标从 0 开始),否则返回 -1;
数据范围:0≤len(nums)≤2×10^5 , 数组中任意值满足 ∣val∣≤10^9;
进阶:时间复杂度 O(logn) ,空间复杂度O(1);
示例1:
示例2:
示例3:




解题分析:
解题思路:
题目的主要信息:
- 给定一个元素升序的、无重复数字的整型数组 nums 和一个目标值 target
- 找到目标值的下标
- 如果找不到返回-1
本题是二分查找类型,所以我们采用二分法进行解决;
知识点:分治
分治即“分而治之”,
“分”指的是将一个大而复杂的问题划分成多个性质相同但是规模更小的子问题,子问题继续按照这样划分,直到问题可以被轻易解决;
“治”指的是将子问题单独进行处理。经过分治后的子问题,需要将解进行合并才能得到原问题的解,因此整个分治过程经常用递归来实现。
思路:
本来我们可以遍历数组直接查找,每次检查当前元素是不是要找的值。
for(int i = 0; i < nums.length; i++)
if(nums[i] == target)
return i;
但是这样这个有序的数组我们就没有完全利用起来。我们想想,若是目标值比较小,肯定在前半区间,若是目标值比较大,肯定在后半区间,怎么评价大小?我们可以用中点值作为一个标杆,将整个数组分为两个区间,目标值与中点值比较就能知道它会在哪个区间,这就是分治的思维。
解题步骤:
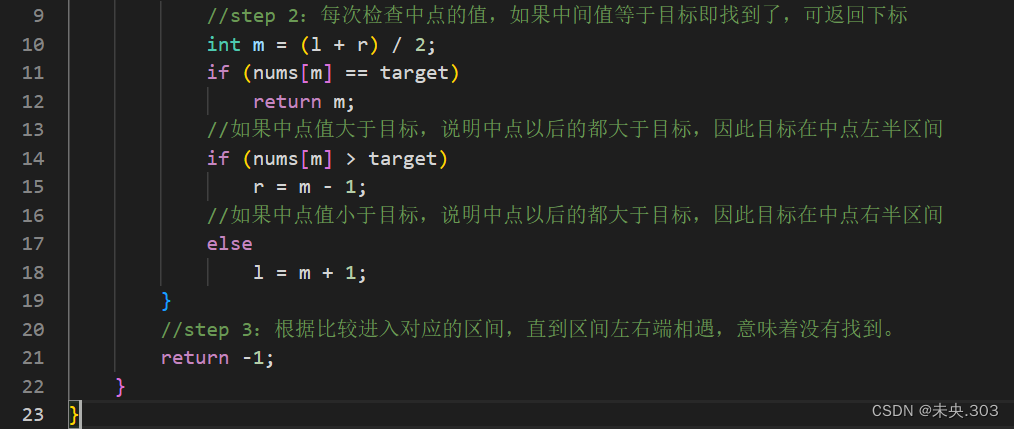
- step 1:从数组首尾开始,每次取中点值。
step 2:如果中间值等于目标即找到了,可返回下标,如果中点值大于目标,说明中点以后的都大于目标,因此目标在中点左半区间,如果中点值小于目标,则相反。
step 3:根据比较进入对应的区间,直到区间左右端相遇,意味着没有找到。
图示说明:
代码编写:

总结
